
微軟AI聊天畫圖炸彈!視覺模型加持ChatGPT,Visual ChatGPT出世
要說ChatGPT已經是核彈級的現象,那麼微軟發布的Visual ChatGPT可以稱的上宇宙大爆炸。在視覺模型加持下的ChatGPT,聊天生圖全拿捏了。
圖文版ChatGPT誕生了!
剛剛,微軟亞研院發布了一個炸彈級模型Visual ChatGPT。
![]()
論文地址:https://arxiv.org/abs/2303.04671
以前的ChatGPT雖然具有卓越的對話能力和推理能力,但也有短板——還不能處理或生成視覺圖像。
而Visual Transformers或Stable Diffusion,雖然在視覺理解和生成能力上很強大,卻只有一輪固定的輸入和輸出。
微軟亞研院學者提出的模型,就把視覺模型信息注入了ChatGPT,使用戶能夠與ChatGPT以語言和圖像的形式交互,還能提供復雜的視覺指令,讓多個模型通過多步驟協作。
微軟前不久推出的Kosmos-1,就屬于多模態大語言模型,傳言下周發布的GPT4,據說也是轉向了多模態。看來,微軟在下一盤多模態的大棋。
作畫、上色、摳圖,一鍵拿捏
注入視覺模型后,ChatGPT直接化身藝術大師,想要什麼作品,動動嘴就行了。
-幫我畫一個蘋果。Visual ChatGPT直接生成了一張畫好的圖。
![]()
這還僅是前菜,Visual ChatGPT各種畫風全能hold住,比如:
隨便給個草圖框架,它便能輸出一幅精美的畫作。
![]()
另外,上色、「摳圖」、深度圖、基于深度圖再生成圖片都能拿捏。
一張簡陋的圖經過你的精心調教后,就變成了這個樣子。
![]()
當然了,Visual ChatGPT沒有忘本,讓它進行創作的同時,還能描述圖片、回答問題。
![]()
有了Visual ChatGPT的加持,微軟必應簡直可以制霸全世界了。
Prompt Manager,讓視覺模型立刻和ChatGPT合體
研究者是如何想到這個點子的呢?
當紅炸子雞ChatGPT能輸入輸出文字類的信息,但是在圖像理解和生成方面能力有限。
Visual ChatGPT并非是從頭訓練的,而是直接基于ChatGPT構建,并向其注入了許多可視化模型(VFMs)。Stable Diffusion就是可視化模型的典型代表。
VFMs雖然在文本-圖像生成上展現出巨大能力,但在人機交互上卻不如對話語言模型靈活。
微軟亞研院的研究人員便get了一個點,將這兩者結合,提出Visual ChatGPT,豈不是強強聯合。
點子有了,那視覺模型信息如何注入ChatGPT呢?就是通過一系列提示。
論文中提出了Prompt Manager,具體步驟是——
1 首先明確告訴ChatGPT每個VFM的能力,并指定輸入-輸出格式。
2 然后轉換不同的視覺信息,比如將Png圖、深度圖和掩模矩陣,轉換為語言格式。
3 最后處理不同VFMs的歷史、優先級和沖突。
![]()
在Prompt Manager的幫助下,ChatGPT可以利用這些VFMs,并以迭代的方式接收其反饋,直到滿足用戶的要求或達到結束條件。
如圖,上傳一個黃色花朵的圖像,然后輸入一個復雜語言指令「請根據圖像的預測深度生成一朵紅色花朵,然后一步一步地把它做成卡通形象」。
Visual ChatGPT便開始執行任務鏈:
首先應用深度估計模型來檢測深度信息,然后利用深度圖像模型生成一個帶有深度信息的紅色花朵圖形,最后利用基于Stable Diffusion的風格轉換VFM,將該圖像轉化為卡通風格。
在上述管道中,Prompt Manager通過提供可視化格式的類型,和記錄信息轉換的過程,來充當ChatGPT的調度器。
最后,當 Visual ChatGPT從Prompt Manager獲得「卡通」提示時,將結束執行管道,并顯示最終結果。
模型概述
對于一個由N個問題-答案對
![]()
構成的集合,想要從第i輪對話中得到答案
![]()
,就需要一系列的VFM和中間輸出。
我們記第i輪對話中,第j次的工具調用中間答案
![]()
。
這種工作機制可用一個公式表示,這個公式也定義了什麼是Visual ChatGPT。
![]()
其他符號代表:P是全局原則,F是各個視覺基礎模型,
![]()
是歷史會話記憶,
![]()
是這一輪的用戶輸入,
![]()
是這輪對話里的推理歷史,
![]()
是中間答案,M是Prompt Manager,用來把上面各個功能轉化成合理的文本prompt,進而將其交給ChatGPT處理。
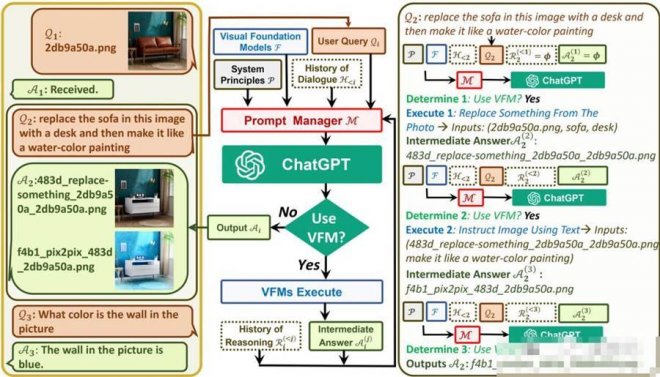
![]()
左邊是進行的三輪對話;中間是Visual ChatGPT如何迭代調用VFMs并提供答案的流程圖;右側是第二個QA的詳細過程。
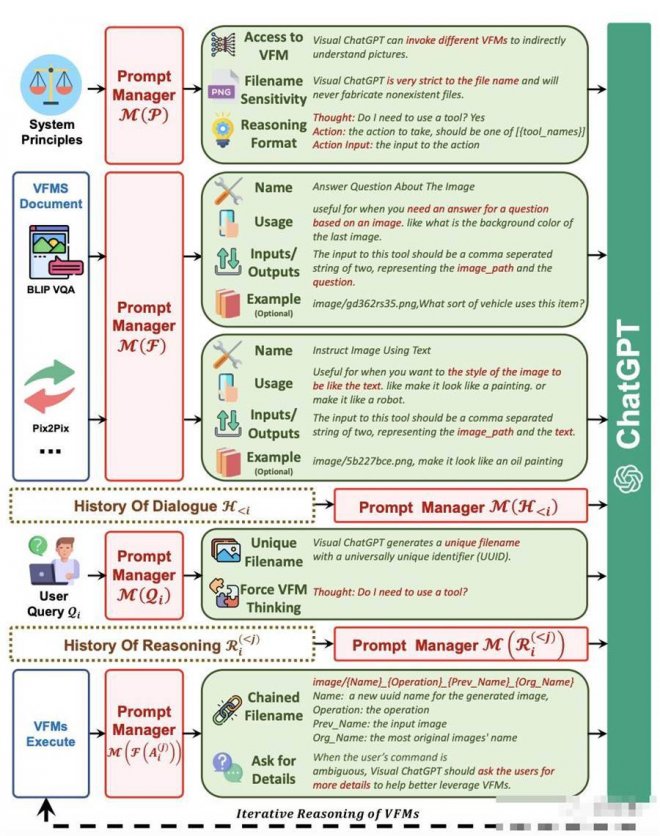
M(P)
Visual ChatGPT為了能讓不同的VFM理解視覺信息并生成相應答案,需要設計一系列系統原則,并將其轉化為ChatGPT能夠理解的提示。
通過生成這樣的提示,Prompt Manager能夠幫助Visual ChatGPT完成生成文本、圖像的任務,能夠訪問一系列VFM并自由選擇使用哪個基礎模型,提高對文件名的敏感度,進行鏈式思考和嚴格推理。
M(F)
Prompt Manager需要幫助Visual ChatGPT區分不同的VFM,以便準確地完成圖像任務。
為此,Prompt Manager對各個基礎模型的名稱、應用場景、輸入和輸出提示以及實例給出了具體定義。
M(Q)
Prompt Manager會對用戶新上傳的圖像生成唯一文件名,并生成假的對話歷史,其中提到該名稱的圖片已經收到,這樣可以在涉及引用現有圖像的查詢時忽略文件名的檢查。
Prompt Manager會在查詢問題之后加上一個后綴提示,來確保成功觸發VFM,強制Visual ChatGPT進行思考,給出言之有物的輸出。
M(F(A))
VFM給出的中間輸出,Prompt Manager會為其生成鏈式文件名,作為下一輪內部對話的輸入。
ChatGPT生成最終答案要經歷一個不斷迭代的過程,它會不斷自我詢問,自動調用更多VFM。而當用戶指令不夠清晰時,Visual ChatGPT會詢問其能否提供更多細節,避免機器自行揣測甚至篡改人類意圖。
![]()
Prompt Manager概述
每個視覺基礎模型的GPU顯存使用情況如下:
![]()
通過修改self.tools來調整模型的使用數量,便可以節省顯存。
案例研究
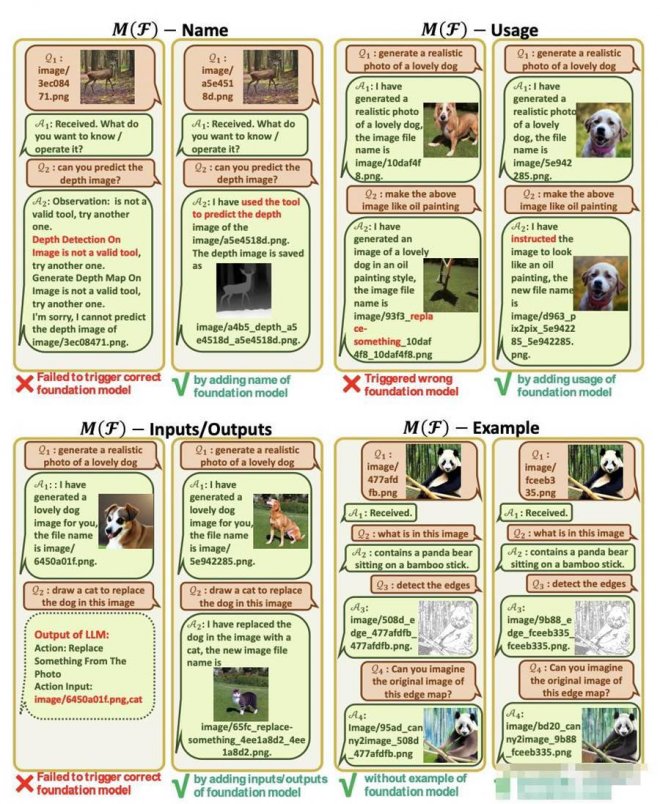
此外,論文還分析了在各個模塊,如果Prompt Manager的設計不到位,會各自出現什麼問題。
比如,對于工具包的描述,需要對其名字、功能、輸入輸出有嚴格的設計。不過舉例影響不大,只要描述清楚,ChatGPT便可以理解。
![]()
另外,在M(P)中,不強調對圖片文件名的敏感,沒有嚴格的思考鏈格式、不強調可靠性、還有可以使用鏈式使用工具,模型在輸出時就會產生錯誤。
論文中,作者也指出了當前Visual ChatGPT存在的一些局限。
比如,需要大量的提示來將VFMs轉換成語言,實時能力有限、token長度有限制等等。
[圖擷取自網路,如有疑問請私訊]
圖文版ChatGPT誕生了!
剛剛,微軟亞研院發布了一個炸彈級模型Visual ChatGPT。

論文地址:https://arxiv.org/abs/2303.04671
以前的ChatGPT雖然具有卓越的對話能力和推理能力,但也有短板——還不能處理或生成視覺圖像。
而Visual Transformers或Stable Diffusion,雖然在視覺理解和生成能力上很強大,卻只有一輪固定的輸入和輸出。
微軟亞研院學者提出的模型,就把視覺模型信息注入了ChatGPT,使用戶能夠與ChatGPT以語言和圖像的形式交互,還能提供復雜的視覺指令,讓多個模型通過多步驟協作。
微軟前不久推出的Kosmos-1,就屬于多模態大語言模型,傳言下周發布的GPT4,據說也是轉向了多模態。看來,微軟在下一盤多模態的大棋。
作畫、上色、摳圖,一鍵拿捏
注入視覺模型后,ChatGPT直接化身藝術大師,想要什麼作品,動動嘴就行了。
-幫我畫一個蘋果。Visual ChatGPT直接生成了一張畫好的圖。

這還僅是前菜,Visual ChatGPT各種畫風全能hold住,比如:
隨便給個草圖框架,它便能輸出一幅精美的畫作。

另外,上色、「摳圖」、深度圖、基于深度圖再生成圖片都能拿捏。
一張簡陋的圖經過你的精心調教后,就變成了這個樣子。

當然了,Visual ChatGPT沒有忘本,讓它進行創作的同時,還能描述圖片、回答問題。

有了Visual ChatGPT的加持,微軟必應簡直可以制霸全世界了。
Prompt Manager,讓視覺模型立刻和ChatGPT合體
研究者是如何想到這個點子的呢?
當紅炸子雞ChatGPT能輸入輸出文字類的信息,但是在圖像理解和生成方面能力有限。
Visual ChatGPT并非是從頭訓練的,而是直接基于ChatGPT構建,并向其注入了許多可視化模型(VFMs)。Stable Diffusion就是可視化模型的典型代表。
VFMs雖然在文本-圖像生成上展現出巨大能力,但在人機交互上卻不如對話語言模型靈活。
微軟亞研院的研究人員便get了一個點,將這兩者結合,提出Visual ChatGPT,豈不是強強聯合。
點子有了,那視覺模型信息如何注入ChatGPT呢?就是通過一系列提示。
論文中提出了Prompt Manager,具體步驟是——
1 首先明確告訴ChatGPT每個VFM的能力,并指定輸入-輸出格式。
2 然后轉換不同的視覺信息,比如將Png圖、深度圖和掩模矩陣,轉換為語言格式。
3 最后處理不同VFMs的歷史、優先級和沖突。
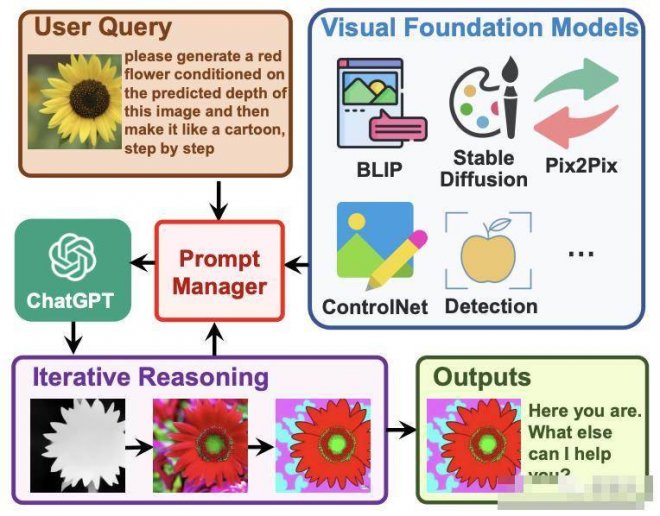
在Prompt Manager的幫助下,ChatGPT可以利用這些VFMs,并以迭代的方式接收其反饋,直到滿足用戶的要求或達到結束條件。
如圖,上傳一個黃色花朵的圖像,然后輸入一個復雜語言指令「請根據圖像的預測深度生成一朵紅色花朵,然后一步一步地把它做成卡通形象」。
Visual ChatGPT便開始執行任務鏈:
首先應用深度估計模型來檢測深度信息,然后利用深度圖像模型生成一個帶有深度信息的紅色花朵圖形,最后利用基于Stable Diffusion的風格轉換VFM,將該圖像轉化為卡通風格。
在上述管道中,Prompt Manager通過提供可視化格式的類型,和記錄信息轉換的過程,來充當ChatGPT的調度器。
最后,當 Visual ChatGPT從Prompt Manager獲得「卡通」提示時,將結束執行管道,并顯示最終結果。
模型概述
對于一個由N個問題-答案對
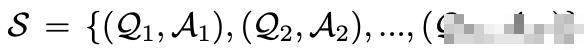
構成的集合,想要從第i輪對話中得到答案
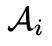
,就需要一系列的VFM和中間輸出。
我們記第i輪對話中,第j次的工具調用中間答案
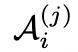
。
這種工作機制可用一個公式表示,這個公式也定義了什麼是Visual ChatGPT。
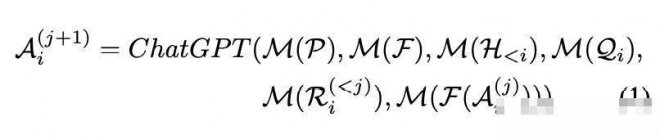
其他符號代表:P是全局原則,F是各個視覺基礎模型,
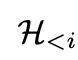
是歷史會話記憶,
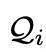
是這一輪的用戶輸入,

是這輪對話里的推理歷史,
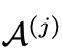
是中間答案,M是Prompt Manager,用來把上面各個功能轉化成合理的文本prompt,進而將其交給ChatGPT處理。
左邊是進行的三輪對話;中間是Visual ChatGPT如何迭代調用VFMs并提供答案的流程圖;右側是第二個QA的詳細過程。
M(P)
Visual ChatGPT為了能讓不同的VFM理解視覺信息并生成相應答案,需要設計一系列系統原則,并將其轉化為ChatGPT能夠理解的提示。
通過生成這樣的提示,Prompt Manager能夠幫助Visual ChatGPT完成生成文本、圖像的任務,能夠訪問一系列VFM并自由選擇使用哪個基礎模型,提高對文件名的敏感度,進行鏈式思考和嚴格推理。
M(F)
Prompt Manager需要幫助Visual ChatGPT區分不同的VFM,以便準確地完成圖像任務。
為此,Prompt Manager對各個基礎模型的名稱、應用場景、輸入和輸出提示以及實例給出了具體定義。
M(Q)
Prompt Manager會對用戶新上傳的圖像生成唯一文件名,并生成假的對話歷史,其中提到該名稱的圖片已經收到,這樣可以在涉及引用現有圖像的查詢時忽略文件名的檢查。
Prompt Manager會在查詢問題之后加上一個后綴提示,來確保成功觸發VFM,強制Visual ChatGPT進行思考,給出言之有物的輸出。
M(F(A))
VFM給出的中間輸出,Prompt Manager會為其生成鏈式文件名,作為下一輪內部對話的輸入。
ChatGPT生成最終答案要經歷一個不斷迭代的過程,它會不斷自我詢問,自動調用更多VFM。而當用戶指令不夠清晰時,Visual ChatGPT會詢問其能否提供更多細節,避免機器自行揣測甚至篡改人類意圖。
Prompt Manager概述
每個視覺基礎模型的GPU顯存使用情況如下:

通過修改self.tools來調整模型的使用數量,便可以節省顯存。
案例研究
此外,論文還分析了在各個模塊,如果Prompt Manager的設計不到位,會各自出現什麼問題。
比如,對于工具包的描述,需要對其名字、功能、輸入輸出有嚴格的設計。不過舉例影響不大,只要描述清楚,ChatGPT便可以理解。
另外,在M(P)中,不強調對圖片文件名的敏感,沒有嚴格的思考鏈格式、不強調可靠性、還有可以使用鏈式使用工具,模型在輸出時就會產生錯誤。
論文中,作者也指出了當前Visual ChatGPT存在的一些局限。
比如,需要大量的提示來將VFMs轉換成語言,實時能力有限、token長度有限制等等。
[圖擷取自網路,如有疑問請私訊]
|
本篇 |
不想錯過? 請追蹤FB專頁! |
| 喜歡這篇嗎?快分享吧! |








相關文章






科普解密








