ChatGPT火了,生成式AI在全球都有哪些場景和應用?
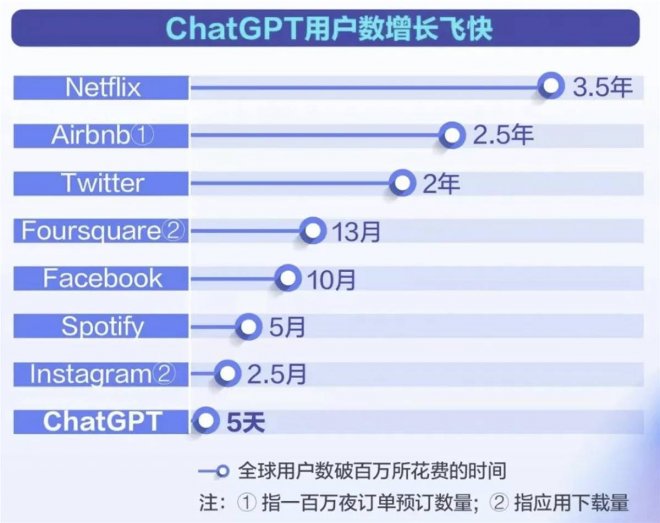
兩個月余時間,月活躍用戶數預計已達1億——ChatGPT的火爆,意味著我們迎來了生成式AI的大浪潮。
人工智能(AI)是一個廣泛的術語,指的是任何能夠進行智能行為的技術。生成式AI是其中一種特定類型的AI,專注于生成新內容,如文本、圖片、音樂等。
回顧2022年的AI格局,正是由生成式AI的大模型(foundation models)所驅動。這些大模型正在迅速從研究實驗室走出來,撲向真實世界的各個場景與應用,2023年影響的層面會更大,發展的速度會更快。另外兩個由大型語言模型 (LLM, large language model) 技術驅動的新興領域,則是幫助人做決策的AI代理(游戲,機器人等), 以及應用在科學領域的AI for Science。
以下是筆者總結的全球范圍內生成式AI的16個方向和場景應用,大致可以分為從文本轉圖片、從文本轉音樂、文本聊天和溝通、文本驅動機器人、文本轉視訊以及AI做科研等幾大類。
![]()
01 Text-to-image 前驅者 DALLE-2
DALLE-2 是擴散模型 (Diffusion Model) 比較具代表性的大模型之一,也是由OpenAI公司所開發的,能根據文本生成逼真的高分辨率的高品質圖像,用于圖像生成。它是基于原先DALL-E(原先用的是GLIDE模型)的版本來改進,具有更高的生成品質和更大的模型尺寸,推動AI在全球的藝術革命。
DALLE-2的核心主要包括CLIP模型和Diffusion模型;CLIP(Contrastive Language-Image Pre-training)是通過將文本與圖像進行對比的預訓練大模型,學習文本與圖像之間的關系,而Diffusion負責聽CLIP的引導生產圖片。
DALLE-2目前還是閉源的,用戶可以通過它的WEB界面或API來使用它。
![]()
02 開源的 Stable Diffusion 橫空出世
繼DALLE-2之后繼續顛覆藝術的革命、也引起技術界轟動的 Stable Diffusion(文中簡稱SD),是一個基于 Latent Diffusion Models(潛在擴散模型)來實現文字轉圖片的大模型,類似DALLE-2和谷歌的Imagen等類似技術,SD可以在短短幾秒鐘內生成清晰度高,還原度佳、風格選擇較廣的AI圖片,這讓SD在同類技術中脫穎而出。
SD最大的突破是任何人都能免費下載并使用其開源代碼,因為模型大小只有幾個G而已!因此在短時間內 huggingface網站上有100萬次模型的下載,也是破了huggingface網站的歷史記錄。這讓AI圖片生成模型不再只是業內少數公司自我標榜技術能力的玩物,許多創業公司和研究室正在快速進入,集成SD模型來開發各種不同場景的應用,包括我們Vitally AI公司。
SD以掩耳盜鈴之勢迅速迭代,開源社區也在不斷改進SD。在SD v2.0上線不到兩周時間,就迅速更新到v2.1版本。相比于前一版本,主要放寬了內容過濾的限制,減少了訓練的誤傷,也有這三大特色:更高品質的圖片、圖像有了景深、負向文本的技巧更好的約束AI生成的隨機性,也支持在單個GPU上來運行。
![]()
![]()
SD官網上寫著 「by the people, for the people」 的使命,與熱烈追求民主化的開源,已被證明是改寫了 AI 賽道的游戲規則,同時也讓Stability AI公司在不到兩年的時間內迅速變成獨角獸公司,快速融資了1億美金。高品質!免費開源!更新快!這幾個關鍵詞就已經決定了Stable Diffusion的出世必定絕不平凡!借助這一突破性技術嘗試給你的寵物照片變個身吧!?
![]()
Vitally AI公司的產品底層就集成了SD的各個版本模型,雖然做成應用,我們在模型底層和產品應用中間層還是要做非常多的工作,不過我們非常看好Stability AI這家公司, 也期待他們下一步能繼續驚世駭俗。
03 谷歌兩個未開源 Text-to-image 擴散模型
2022年Google AI還有兩個Image-to-text模型。Imagen和Parti分別是擴散模型 (Diffusion Model) 和自回歸模型 (Auto-regression model),兩者不同但互補,代表了谷歌兩個不同探索方向,模型都沒有開源或可以集成的API,所以 Vitally 團隊無法動手研究,但論文仍是富有有趣的見解。不管這些大模型再怎麼厲害,對Vitally AI這樣做產品應用的公司而言,「只能仰望和遠觀,不能褻玩焉」。
Imagen大模型網址: imagen.research.google
![]()
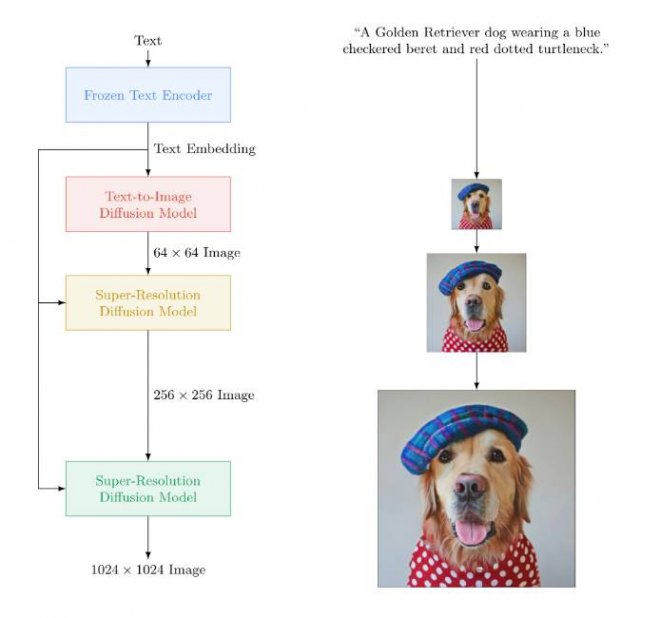
Imagen不同于其他已知的文本出圖的大模型,其更注重深層次的語言理解。Imagen的預訓練語言模型(T5-XXL)的訓練集包含800GB的純文本語料,在文本理解能力上會比有限圖文訓練的效果更強。Imagen的工作流程為:在輸入prompt后,如「一只戴著藍色格子貝雷帽和紅色波點高領毛衣的金毛犬」(A golden retriever dog wearing a blue checkered beret and red dotted turtleneck),Imagen先使用谷歌自研的T5-XXL編碼器將輸入文本編碼為嵌入,再利用一系列擴散模型,從分辨率 64×64 → 256×256 → 1024×1024的過程來生成圖片。結果表明,預訓練大語言模型和多聯擴散模型在生成高保真圖片方面效果很好。
![]()
Parti大模型網址: parti.research.google
![]()
Parti是一種自回歸文本生成圖片模型(Pathways Auto-regressive Text-to-Image model),其將文本到圖片的生成視為序列到序列的建模問題,類似于機器翻譯,這使其受益于大語言模型的進步。在輸出圖片token序列后,Parti使用圖像標記器 ViT-VQGAN將圖片編碼為離散token序列,并利用其重建圖片token序列的能力,使其成為高品質、視覺多樣化的圖像。
![]()
04 將顛覆搜索并沖擊許多領域的ChatGPT!
ChatGPT!史上唯一5天內獲得100萬用戶的應用,兩個月時間用戶量達1億,打破上個記錄保持者——用9個月時間將用戶量沖上1億的TikTok。ChatGPT的快速發展與日益智能的知識助理角色,挑戰了像谷歌這樣的傳統信息搜索巨頭的產品形態與商業模式。
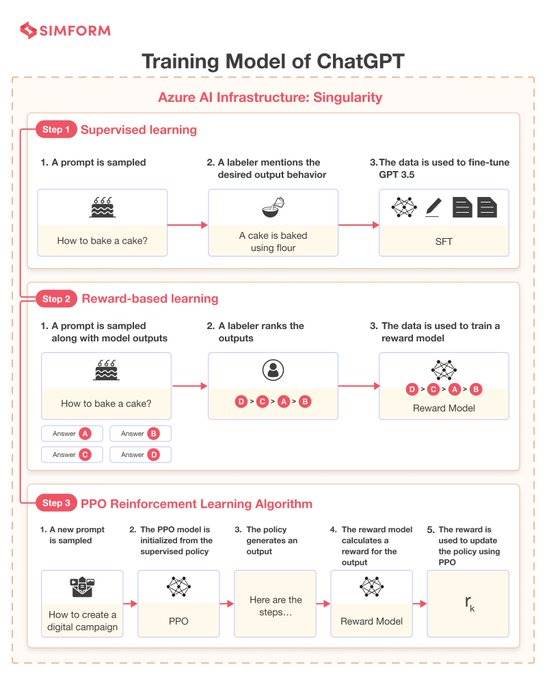
ChatGPT讓機器學習如何更好地理解人類語言,從而更好地回答問題,更好地跟人類寫作,甚至近一步啟發人類的創造力。本次OpenAI發布的ChatGPT是基于GPT-3的微調版本,即GPT-3.5。它使用了一種新技術RLHF(「人類反饋強化學習」)。相比GPT-3,ChatGPT的主要提升點在于記憶能力,可實現高度擬人化的連續對話和問答,也可以按輸入的具體指令產出特定的文本格式。
![]()
在各種社區的討論中被總結出幾十種ChatGPT內容產出的的場景與用例,比如:投資研究報告、工作周報、論文摘要、合同文本、招聘說明書、指定計算機語言的代碼等等。ChatGPT會關注 Vitally AI 微信公眾號,我們后續的選題規劃,會整理出一篇文章,總結出幾十種ChatGPT的使用方式。
當然,ChatGPT也有人工智障的時候,比如:對人類的知識只截止到2021年底,所以實時信息的搜索還是得借助搜索引擎;ChatGPT數學不好;或是如果問它不合邏輯的問題,它會被繞暈。
![]()
目前 GhatGPT的極致能力展現在:通過美國醫療專業執照的考試,通過美國知名商學院沃頓的MBA考試等接近人的水平。某種意義上,ChatGPT越來越像一個「真實的人」,只要算力足夠強大,它與人類的互動越多,就將「成長」越快,也能具備更好的邏輯「思考」結果。只要時間足夠長,人工智能的能力將持續提升和擴展。因此,也引發了學術界的抗爭、與法律與倫理相關問題的諸多討論與隱憂。
學術界反抗ChatGPT的力量,包括美國斯坦福團隊推出DetectGPT,阻止學生用AI寫作業。另一個由一位華裔學生 Edward 創建的GPTZero,用于檢測文本是否由人工智能寫作出來的。它使用兩個指標「困惑度」和「突發性」來衡量文本的復雜度,如果GPTZero對文本感到困惑,則其復雜度較高,更判定可能是人工所編寫的。
ChatGPT是個超級重磅的話題,2023 年對ChatGPT未來的揣想,我們在后續的文章中,再來繼續探討吧~
05 用文本來驅動機器人Text-to-robot !
如何給GPT手臂和腿,讓它們能夠清理你整潔的廚房?不像NLP 自然語言處理的人工智能技術,機器人模型需要與物理世界互動。今年,大型的預訓練模型終于開始解決機器人技術中困難的多模態問題。機器人技術中的任務規范有多種形式,如模仿一次性演示、遵循語言指示和達到視覺目標。它們通常被認為是不同的任務,由專門的模塊來處理。
由英偉達等機構研發的VIMA用多模態的提示來表達廣泛的機器人操縱任務。如此一來,它就可以用單一的模塊來處理文本和視覺標記的提示,并自動輸出運動動作。為了訓練和評估VIMA,他們開發了新的模擬基準,其中有數千個程序化生成的任務和60萬以上專家軌跡用于模仿學習。VIMA在模型容量和數據大小方面都實現了強大的可擴展性。在相同的訓練數據下,它在最難的zero-shot泛化設置中優于先前的SOTA方法,任務成功率高達 2.9倍。在訓練數據減少10倍的情況下,VIMA的表現仍然比競爭方法好2.7倍。
![]()
與VIMA類似,GoogleAI的研究人員發布了RT-1,一種多模態機器人變換器。它將機器人的輸入和輸出動作(如相機圖像、任務指令和電機命令)標記化,以便在運行時進行有效的推理。RT-1使用13個Everyday Robots(EDR)機器人收集的數據進行訓練,包括了700多項任務、13萬時間片段。與之前的技術相比,RT-1可以對新的任務、環境和物體表現出明顯改善的 zero-shot 泛化能力。
![]()
06 萬眾期待的Text-to-Video
在文本生成視訊領域,我們想向大家介紹三款頭部的研究,他們分別來自于 Meta,Google 和 Phenaki。
如果你是一名創作者,當你將文本轉化成圖片后,一個很自然的想法是:希望能讓圖片動起來,形成一個視訊,從而展示更豐富的細節。Meta公司研究的「Make-A-Video」 中的Text-to-Video模型就完成了這樣一件事:當輸入小馬在喝水時,模型就會根據文字生成一個小馬喝水的視訊。
![]()
![]()
Text-to-Video模型采用無監督學習的方法生成視訊數據集,并且通過插值網絡進行調整,他的模型結構可以概括如下:
![]()
無獨有偶,谷歌也發布了自己的文字生成視訊的產品 Imagen Video: 基于Video Diffusion Models(擴散模型)的視訊生成模型。該模型最終生成128張圖片,并在每秒內播放24張,最終形成5.8s的高清視訊。
https://imagen.research.google/video/
相關的頭部模型還有Phenaki: 使用Causal Model(因果模型)來通過文字生成視訊,他們的模型考慮了時間變量,因此可以生成任意時長的視訊。
短視訊是互聯網巨頭的必爭之地,所以Text-to-Video的發展也備受矚目,不過Vitally AI觀點是,這些巨頭的技術研究不見得愿意開源出來,因為牽涉到巨大的商業利益。另外,這個領域可能也不是小創業團隊的事,因為即便你有好的視訊預訓練大模型,視訊素材的數據取得與訓練,是一個成本高昂的問題。
07 Tune-A-Video調整視訊生成
Tune-A-Video最初是由Google在2023年1月發表的一篇論文中提出的,展示了僅使用文本提示即可生成簡單的 YouTube視訊。這是一種使用單個文本-視訊對進行模型微調的文本生成視訊生成方法,它是從預訓練 Text-to-imae 的擴散式模型進行擴展而來的。訓練過程中僅更新了注意力塊中的投影矩陣。Tune-A-Video支持在個性化的 DreamBooth訓練與模型微調,以及在 Modern Disney and Redshift數據集上進行視訊調整。
https://tuneavideo.github.io/
這種文本到視訊生成方法最近被新加坡國立大學的 Show Lab 的研究人員進一步改進,解決了單個文本-視訊對訓練的問題。通過使用自定義的稀疏因果關注機制(customised Sparse-Causal Attention),Tune-A-Video將空間自注意力(spatial self-attention)擴展到時空域(spatiotemporal domain),使用預訓練的文本到圖像擴散模型。
https://tuneavideo.github.io/
08 Text-to-3D 恐怕還要再等等
從設計創新產品到電影和游戲中令人驚嘆的視覺效果,3D建模將是創意AI領域實現從文本到想法的下一步。2022年已經出現了幾個原始但極具潛力的3D生成模型!
DreamFusion:Google AI 的DreamFusion,可將文本轉換為3D生成的圖像。它將文中上述提過的文本出圖 Imagen大模型與NeRF的3D功能結合在一起,生成適用于AR項目或作為雕塑基礎網格的品質較高的紋理3D模型,可以從任意角度查看,并可根據不同的照明條件重新照明。Dream Fusion AI還可以根據生成圖像模型的2D圖像生成3D模型。
![]()
Nvidia英偉達公司則有兩項重要的研究成果:Magic3D和Get3D,目標是通過允許用戶從文本生成3D模型,使3D內容創建更加容易。Magic3D是一種高分辨率的文本到3D內容創建方法,它采用內容從粗略到精細的漸進過程,利用低分辨率和高分辨率的擴散先驗來學習目標內容的3D表現。據媒體報道,它比Google的DreamFusion快2倍,僅需40分鐘即可創建高品質的3D網格模型。Get3D是一個AI模型,結合了自然語言(NLP)和計算機視覺技術,用文本描述生成逼真的3D對象。這使用戶可以快速創建逼真的3D模型,無需任何先前的建模技能。
![]()
![]()
Vitally AI認為Text-to-3D全球都在比較早期的階段, 因為也沒有開源,所以業界無法研究和參與。我們曾經跟其他AI創業者交流,他們用Diffusion Model和Nerf放在一起做實驗,有點樣子,但是最大的障礙還是全球領域能做訓練的3D圖像數據少之又少,而用技術的方法制造AI訓練用的數據成本也很高,我們仍需耐心等候。
09 AI自己玩 Minecraft !?
Minecraft 「我的世界」這個游戲絕對是一個完美的通用智能測試平台,因為:
它是無限開放的,可以提供各種各樣的行為動作。 它具有多種類型的物理和邏輯約束。 它具有許多不同的任務和目標。
2022年我們看到一些實驗室和公司使用Transformer大模型來訓練AI 在Minecraft中執行各種任務的成功案例。這些大模型可以建造城堡,挖掘礦物,甚至與其他玩家交互。
![]()
為了利用互聯網上大量可用的未標記視訊數據,OpenAI開發了一種視訊預訓練 (VPT) 算法。首先向游戲商家收集2,000小時的少量數據集,其數據集記錄游戲視訊,也記錄了玩家采取的行動(按鍵操作和鼠標移動)。利用這些數據,訓練出一個逆動力學模型(IDM)以 「預測」 視訊中每個步驟所采取得動作。通過使用經過訓練的 IDM模型來標記更多的在線視訊數據,并通過行為克隆來建立學習的行為。AI通過觀看70,000小時YouTube視訊的大數據量就可以被訓練自己玩Minecraft。
![]()
Nvidia還開發了一個名為 MineDojo的AI代理,可以根據 Minecraft中的文字提示執行操作,并獲得了國際機器學習會議的杰出論文獎。微軟也有一個新的AI Minecraft「代理」,它在游戲內運行 。
10 AI 發現新材料
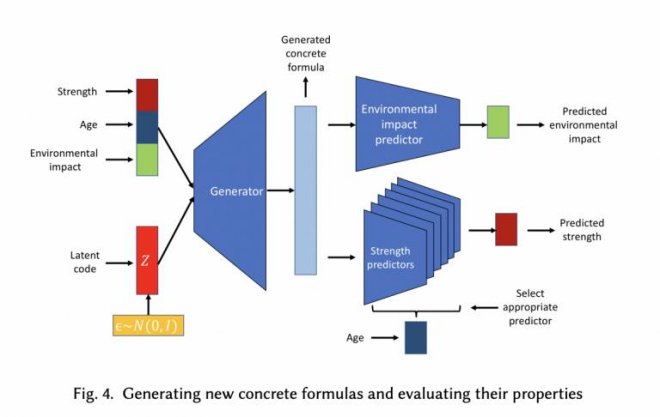
AI在材料科學領域的應用正在快速發展,其中AI發現新材料是一項重要的技術。這項技術包含了數據挖掘和機器學習兩個步驟。數據挖掘通過從大量數據中提取有用信息來實現。AI通過對數據的分析,提取有關材料性能的信息。機器學習是通過利用算法從數據中學習來實現的。在這個步驟中,AI利用算法預測新材料的性能。這個可能更偏向 Analytical AI。
今年,GoogleAI發布了一種名為「Material Discovery」的模型,該模型可以根據給定的物理和化學性質生成新的材料結構。這項技術有望在未來幫助材料科學家發現更高性能的材料。然而,也存在一些挑戰,其中一個是數據缺乏。這項技術需要大量數據來做出準確的預測,如果數據不足,AI可能會做出不準確的預測。另一個挑戰是材料的復雜性。由于材料是復雜的系統,AI可能無法準確預測材料在不同環境中的性能。
![]()
11 AI 助力醫學研究
Google旗下公司Deep Mind的AlphaFold (2021) ,是全球第一個能夠準確預測蛋白質3D結構的模型。同年7月,Deep Mind宣布了「蛋白質宇宙」—— 擴大 AlphaFold 的蛋白質數據庫至200M種結構,這簡直是非常珍貴的科學瑰寶!AI在醫學研究領域的應用(AI for Science)也在迅速發展,特別是OpenAI公司的CEO - Sam Altman接下來也非常看好的領域。
![]()
2022年GoogleAI發布了一種名為 「MedGPT」 的模型,該模型可以根據病人的病史和影像學數據生成診斷和治療建議。這項技術有望幫助醫生更快更準確地診斷疾病,并且還可以幫助研究人員發現新的治療方法。同年,費城生物醫學工程卓克索大學的一項研究發現,ChatGPT可以通過和人類的對話,幫助發現是否有阿爾茨海默氏病的早期癥狀,準確率達80%,高于使用傳統方法的74.6%的正確率,從而及時提示患病風險。文章前面提到過,GhatGPT的極致能力已經展現在可以通過美國醫療專業執照的考試。
12 AI可以通過網絡視訊學習嗎?——VPT(「視訊預訓練」)模型
AI 可以學習人類復雜的動作嗎?可以!Jeff clune 的團隊發布了VPT(「視訊預訓練」)模型,它甚至可以通過學習自己玩「我的世界」(Minecraft)!在「我的世界」中,一個人制作鉆石工具需要完成2萬多個動作,花費20分鐘,VPT通過學習記錄了人們點擊鍵盤鼠標的操作,居然學會了自己在我的世界中完成這些動作。
換句話說,只要知道了鼠標和鍵盤的點擊移動順序,VPT可以通過Inverse Dynamic Model(逆向動力模型)學習一切我們認為只有人類才能做到的復雜動作,比如如果我們可以準確記錄數字繪畫家在電子屏幕上的操作順序,那麼模型也可以模仿數字繪畫家繪制一幅美麗的日落,VPT為AI通過互聯網上的視訊來學習鋪平了道路!
13 AI 代理在談判上的突破
多年來,人們提出了許多用于外交的人工智能方法,主要依賴手工制定的協議和基于規則的系統,但遠遠落后于人的表現(無論有無溝通)。
Meta公司的人工智能CICERO 是第一個在外交游戲中達到人類水平表現的AI代理,在游戲《外交》中,Cicero具有對他人的信仰、目標和意圖進行推理的能力,可以通過表現同理心、使用人類語言交流并建立人際關系,同時能夠有效地說服甚至欺騙,來達到在游戲中獲勝的目的。
與此同時,DeepMind公司也宣布了他們的外交游戲 AI 代理。試想,如果CICERO與 DeepMind的AI對戰會發生什麼?
![]()
14 Music-to-text 音頻生成文本
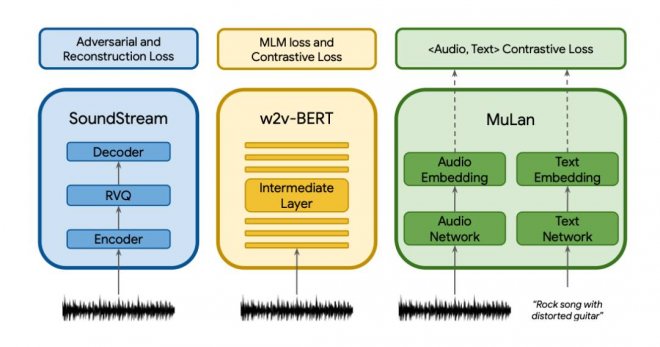
Whisper 是由OpenAI開發的一個大型開源音頻識別模型。它在英語的語音識別方面達到了接近人類水平的準確性和魯棒性(在語音識別中,「魯棒性」通常指一個模型的能力,即在嘈雜或有干擾的環境下識別語音的準確性和可靠性)。與其他模型不同的是,Whisper使用了更大以及更多樣的訓練數據集。它使用網絡上的共680,000小時的音頻數據進行訓練,這些數據是多語言和多任務的,使得Whisper除了能將英語轉成英文,還能將幾乎所有語種聲音轉成對應文字以及翻譯成英語。
Whisper提供了多種大小的英語/多語言模型,使得開發者能夠在識別速度和識別品質中權衡。對于英語任務,開發者使用較小的模型便可達到良好的效果,識別速度甚至可以達到實時處理的效果。如果使用大模型,識別準確性則可以說超越所有現有商業公司產品。對于漢語任務,開發者必須使用大模型才能達到較準確的識別,識別速度與中國商業公司的產品相比有一定差距。
![]()
15 Text-to-music 文本指令生成音樂
MusicLM是由谷歌研究院在近日發布的文本生成音樂模型,只發布了論文與數據集,沒有開源。模型可以從文本描述例如 「平靜的小提琴旋律伴著扭曲的吉他旋律」生成高保真的音樂。MusicLM將文本指示的音樂生成過程描述為一個層次化的序列到序列的建模任務。它生成的音樂頻率為24kHz,在幾分鐘內保持一致。
與之前的模型相比,MusicLM在音頻品質和對文本描述的遵守方面都更優。此外,MusicLM可以以文本描述的旋律為條件,它可以根據文本說明中描述的風格來轉換口哨和哼唱的旋律。為了支持未來的研究,谷歌研究院一并公開發布了MusicCaps。這是一個由5.5K音樂-文本對組成的數據集,有人類專家提供的豐富文本描述。
![]()
16 別忘記了亞馬遜云的存在
Amazon SageMaker是在亞馬遜云上的一站式大模型開發平台,可以提高大模型的開發效率。在IDC發布的報告中,Amazon SageMaker被列入「領導者」陣營,并居于圖中最高最遠的位置。
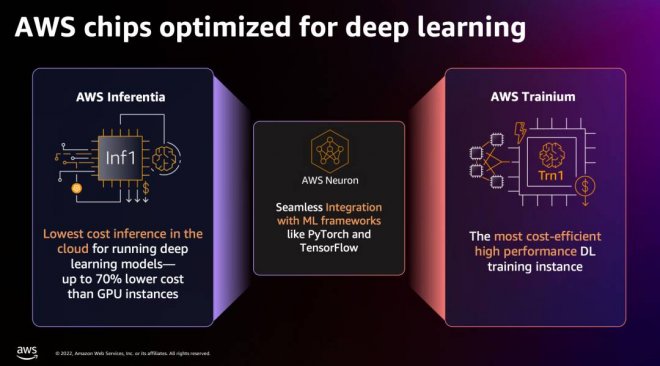
亞馬遜云科技自研AI芯片可以提供更具性價比的方案,例如Amazon Trainium自研芯片的Amazon EC2 Trn1實例可節省高達50%的訓練成本,而Inf2實例可支持橫向擴展分布式推理,方便部署并提升高速推理。
![]()
Stability AI選擇AWS作為唯一云服務提供商,在AWS平台上搭建了大規模訓練集群。使用SageMaker Jumpstart預集成的SD2.0預訓練模型和優化庫,Stability AI能夠使其模型訓練具有更高韌性和性能,訓練時間和成本可減少58%(這是很多錢)。
![]()
(文章僅代表作者觀點)
[圖擷取自網路,如有疑問請私訊]
人工智能(AI)是一個廣泛的術語,指的是任何能夠進行智能行為的技術。生成式AI是其中一種特定類型的AI,專注于生成新內容,如文本、圖片、音樂等。
回顧2022年的AI格局,正是由生成式AI的大模型(foundation models)所驅動。這些大模型正在迅速從研究實驗室走出來,撲向真實世界的各個場景與應用,2023年影響的層面會更大,發展的速度會更快。另外兩個由大型語言模型 (LLM, large language model) 技術驅動的新興領域,則是幫助人做決策的AI代理(游戲,機器人等), 以及應用在科學領域的AI for Science。
以下是筆者總結的全球范圍內生成式AI的16個方向和場景應用,大致可以分為從文本轉圖片、從文本轉音樂、文本聊天和溝通、文本驅動機器人、文本轉視訊以及AI做科研等幾大類。
01 Text-to-image 前驅者 DALLE-2
DALLE-2 是擴散模型 (Diffusion Model) 比較具代表性的大模型之一,也是由OpenAI公司所開發的,能根據文本生成逼真的高分辨率的高品質圖像,用于圖像生成。它是基于原先DALL-E(原先用的是GLIDE模型)的版本來改進,具有更高的生成品質和更大的模型尺寸,推動AI在全球的藝術革命。
DALLE-2的核心主要包括CLIP模型和Diffusion模型;CLIP(Contrastive Language-Image Pre-training)是通過將文本與圖像進行對比的預訓練大模型,學習文本與圖像之間的關系,而Diffusion負責聽CLIP的引導生產圖片。
DALLE-2目前還是閉源的,用戶可以通過它的WEB界面或API來使用它。

02 開源的 Stable Diffusion 橫空出世
繼DALLE-2之后繼續顛覆藝術的革命、也引起技術界轟動的 Stable Diffusion(文中簡稱SD),是一個基于 Latent Diffusion Models(潛在擴散模型)來實現文字轉圖片的大模型,類似DALLE-2和谷歌的Imagen等類似技術,SD可以在短短幾秒鐘內生成清晰度高,還原度佳、風格選擇較廣的AI圖片,這讓SD在同類技術中脫穎而出。
SD最大的突破是任何人都能免費下載并使用其開源代碼,因為模型大小只有幾個G而已!因此在短時間內 huggingface網站上有100萬次模型的下載,也是破了huggingface網站的歷史記錄。這讓AI圖片生成模型不再只是業內少數公司自我標榜技術能力的玩物,許多創業公司和研究室正在快速進入,集成SD模型來開發各種不同場景的應用,包括我們Vitally AI公司。
SD以掩耳盜鈴之勢迅速迭代,開源社區也在不斷改進SD。在SD v2.0上線不到兩周時間,就迅速更新到v2.1版本。相比于前一版本,主要放寬了內容過濾的限制,減少了訓練的誤傷,也有這三大特色:更高品質的圖片、圖像有了景深、負向文本的技巧更好的約束AI生成的隨機性,也支持在單個GPU上來運行。


SD官網上寫著 「by the people, for the people」 的使命,與熱烈追求民主化的開源,已被證明是改寫了 AI 賽道的游戲規則,同時也讓Stability AI公司在不到兩年的時間內迅速變成獨角獸公司,快速融資了1億美金。高品質!免費開源!更新快!這幾個關鍵詞就已經決定了Stable Diffusion的出世必定絕不平凡!借助這一突破性技術嘗試給你的寵物照片變個身吧!?

Vitally AI公司的產品底層就集成了SD的各個版本模型,雖然做成應用,我們在模型底層和產品應用中間層還是要做非常多的工作,不過我們非常看好Stability AI這家公司, 也期待他們下一步能繼續驚世駭俗。
03 谷歌兩個未開源 Text-to-image 擴散模型
2022年Google AI還有兩個Image-to-text模型。Imagen和Parti分別是擴散模型 (Diffusion Model) 和自回歸模型 (Auto-regression model),兩者不同但互補,代表了谷歌兩個不同探索方向,模型都沒有開源或可以集成的API,所以 Vitally 團隊無法動手研究,但論文仍是富有有趣的見解。不管這些大模型再怎麼厲害,對Vitally AI這樣做產品應用的公司而言,「只能仰望和遠觀,不能褻玩焉」。
Imagen大模型網址: imagen.research.google

Imagen不同于其他已知的文本出圖的大模型,其更注重深層次的語言理解。Imagen的預訓練語言模型(T5-XXL)的訓練集包含800GB的純文本語料,在文本理解能力上會比有限圖文訓練的效果更強。Imagen的工作流程為:在輸入prompt后,如「一只戴著藍色格子貝雷帽和紅色波點高領毛衣的金毛犬」(A golden retriever dog wearing a blue checkered beret and red dotted turtleneck),Imagen先使用谷歌自研的T5-XXL編碼器將輸入文本編碼為嵌入,再利用一系列擴散模型,從分辨率 64×64 → 256×256 → 1024×1024的過程來生成圖片。結果表明,預訓練大語言模型和多聯擴散模型在生成高保真圖片方面效果很好。
Parti大模型網址: parti.research.google

Parti是一種自回歸文本生成圖片模型(Pathways Auto-regressive Text-to-Image model),其將文本到圖片的生成視為序列到序列的建模問題,類似于機器翻譯,這使其受益于大語言模型的進步。在輸出圖片token序列后,Parti使用圖像標記器 ViT-VQGAN將圖片編碼為離散token序列,并利用其重建圖片token序列的能力,使其成為高品質、視覺多樣化的圖像。
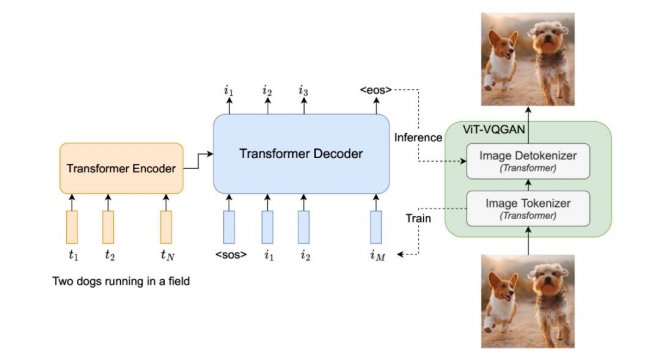
04 將顛覆搜索并沖擊許多領域的ChatGPT!
ChatGPT!史上唯一5天內獲得100萬用戶的應用,兩個月時間用戶量達1億,打破上個記錄保持者——用9個月時間將用戶量沖上1億的TikTok。ChatGPT的快速發展與日益智能的知識助理角色,挑戰了像谷歌這樣的傳統信息搜索巨頭的產品形態與商業模式。
ChatGPT讓機器學習如何更好地理解人類語言,從而更好地回答問題,更好地跟人類寫作,甚至近一步啟發人類的創造力。本次OpenAI發布的ChatGPT是基于GPT-3的微調版本,即GPT-3.5。它使用了一種新技術RLHF(「人類反饋強化學習」)。相比GPT-3,ChatGPT的主要提升點在于記憶能力,可實現高度擬人化的連續對話和問答,也可以按輸入的具體指令產出特定的文本格式。
在各種社區的討論中被總結出幾十種ChatGPT內容產出的的場景與用例,比如:投資研究報告、工作周報、論文摘要、合同文本、招聘說明書、指定計算機語言的代碼等等。ChatGPT會關注 Vitally AI 微信公眾號,我們后續的選題規劃,會整理出一篇文章,總結出幾十種ChatGPT的使用方式。
當然,ChatGPT也有人工智障的時候,比如:對人類的知識只截止到2021年底,所以實時信息的搜索還是得借助搜索引擎;ChatGPT數學不好;或是如果問它不合邏輯的問題,它會被繞暈。
目前 GhatGPT的極致能力展現在:通過美國醫療專業執照的考試,通過美國知名商學院沃頓的MBA考試等接近人的水平。某種意義上,ChatGPT越來越像一個「真實的人」,只要算力足夠強大,它與人類的互動越多,就將「成長」越快,也能具備更好的邏輯「思考」結果。只要時間足夠長,人工智能的能力將持續提升和擴展。因此,也引發了學術界的抗爭、與法律與倫理相關問題的諸多討論與隱憂。
學術界反抗ChatGPT的力量,包括美國斯坦福團隊推出DetectGPT,阻止學生用AI寫作業。另一個由一位華裔學生 Edward 創建的GPTZero,用于檢測文本是否由人工智能寫作出來的。它使用兩個指標「困惑度」和「突發性」來衡量文本的復雜度,如果GPTZero對文本感到困惑,則其復雜度較高,更判定可能是人工所編寫的。
ChatGPT是個超級重磅的話題,2023 年對ChatGPT未來的揣想,我們在后續的文章中,再來繼續探討吧~
05 用文本來驅動機器人Text-to-robot !
如何給GPT手臂和腿,讓它們能夠清理你整潔的廚房?不像NLP 自然語言處理的人工智能技術,機器人模型需要與物理世界互動。今年,大型的預訓練模型終于開始解決機器人技術中困難的多模態問題。機器人技術中的任務規范有多種形式,如模仿一次性演示、遵循語言指示和達到視覺目標。它們通常被認為是不同的任務,由專門的模塊來處理。
由英偉達等機構研發的VIMA用多模態的提示來表達廣泛的機器人操縱任務。如此一來,它就可以用單一的模塊來處理文本和視覺標記的提示,并自動輸出運動動作。為了訓練和評估VIMA,他們開發了新的模擬基準,其中有數千個程序化生成的任務和60萬以上專家軌跡用于模仿學習。VIMA在模型容量和數據大小方面都實現了強大的可擴展性。在相同的訓練數據下,它在最難的zero-shot泛化設置中優于先前的SOTA方法,任務成功率高達 2.9倍。在訓練數據減少10倍的情況下,VIMA的表現仍然比競爭方法好2.7倍。
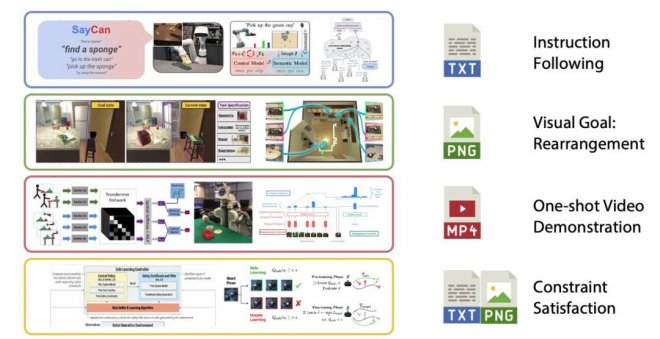
與VIMA類似,GoogleAI的研究人員發布了RT-1,一種多模態機器人變換器。它將機器人的輸入和輸出動作(如相機圖像、任務指令和電機命令)標記化,以便在運行時進行有效的推理。RT-1使用13個Everyday Robots(EDR)機器人收集的數據進行訓練,包括了700多項任務、13萬時間片段。與之前的技術相比,RT-1可以對新的任務、環境和物體表現出明顯改善的 zero-shot 泛化能力。

06 萬眾期待的Text-to-Video
在文本生成視訊領域,我們想向大家介紹三款頭部的研究,他們分別來自于 Meta,Google 和 Phenaki。
如果你是一名創作者,當你將文本轉化成圖片后,一個很自然的想法是:希望能讓圖片動起來,形成一個視訊,從而展示更豐富的細節。Meta公司研究的「Make-A-Video」 中的Text-to-Video模型就完成了這樣一件事:當輸入小馬在喝水時,模型就會根據文字生成一個小馬喝水的視訊。


Text-to-Video模型采用無監督學習的方法生成視訊數據集,并且通過插值網絡進行調整,他的模型結構可以概括如下:
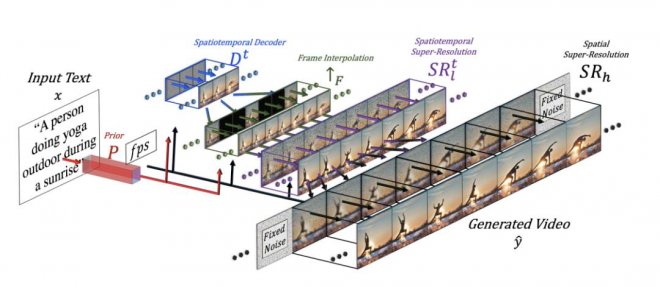
無獨有偶,谷歌也發布了自己的文字生成視訊的產品 Imagen Video: 基于Video Diffusion Models(擴散模型)的視訊生成模型。該模型最終生成128張圖片,并在每秒內播放24張,最終形成5.8s的高清視訊。
https://imagen.research.google/video/
相關的頭部模型還有Phenaki: 使用Causal Model(因果模型)來通過文字生成視訊,他們的模型考慮了時間變量,因此可以生成任意時長的視訊。
短視訊是互聯網巨頭的必爭之地,所以Text-to-Video的發展也備受矚目,不過Vitally AI觀點是,這些巨頭的技術研究不見得愿意開源出來,因為牽涉到巨大的商業利益。另外,這個領域可能也不是小創業團隊的事,因為即便你有好的視訊預訓練大模型,視訊素材的數據取得與訓練,是一個成本高昂的問題。
07 Tune-A-Video調整視訊生成
Tune-A-Video最初是由Google在2023年1月發表的一篇論文中提出的,展示了僅使用文本提示即可生成簡單的 YouTube視訊。這是一種使用單個文本-視訊對進行模型微調的文本生成視訊生成方法,它是從預訓練 Text-to-imae 的擴散式模型進行擴展而來的。訓練過程中僅更新了注意力塊中的投影矩陣。Tune-A-Video支持在個性化的 DreamBooth訓練與模型微調,以及在 Modern Disney and Redshift數據集上進行視訊調整。
https://tuneavideo.github.io/
這種文本到視訊生成方法最近被新加坡國立大學的 Show Lab 的研究人員進一步改進,解決了單個文本-視訊對訓練的問題。通過使用自定義的稀疏因果關注機制(customised Sparse-Causal Attention),Tune-A-Video將空間自注意力(spatial self-attention)擴展到時空域(spatiotemporal domain),使用預訓練的文本到圖像擴散模型。
https://tuneavideo.github.io/
08 Text-to-3D 恐怕還要再等等
從設計創新產品到電影和游戲中令人驚嘆的視覺效果,3D建模將是創意AI領域實現從文本到想法的下一步。2022年已經出現了幾個原始但極具潛力的3D生成模型!
DreamFusion:Google AI 的DreamFusion,可將文本轉換為3D生成的圖像。它將文中上述提過的文本出圖 Imagen大模型與NeRF的3D功能結合在一起,生成適用于AR項目或作為雕塑基礎網格的品質較高的紋理3D模型,可以從任意角度查看,并可根據不同的照明條件重新照明。Dream Fusion AI還可以根據生成圖像模型的2D圖像生成3D模型。

Nvidia英偉達公司則有兩項重要的研究成果:Magic3D和Get3D,目標是通過允許用戶從文本生成3D模型,使3D內容創建更加容易。Magic3D是一種高分辨率的文本到3D內容創建方法,它采用內容從粗略到精細的漸進過程,利用低分辨率和高分辨率的擴散先驗來學習目標內容的3D表現。據媒體報道,它比Google的DreamFusion快2倍,僅需40分鐘即可創建高品質的3D網格模型。Get3D是一個AI模型,結合了自然語言(NLP)和計算機視覺技術,用文本描述生成逼真的3D對象。這使用戶可以快速創建逼真的3D模型,無需任何先前的建模技能。

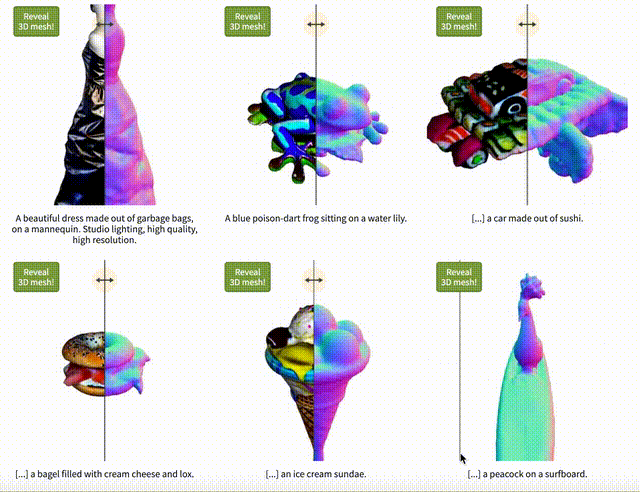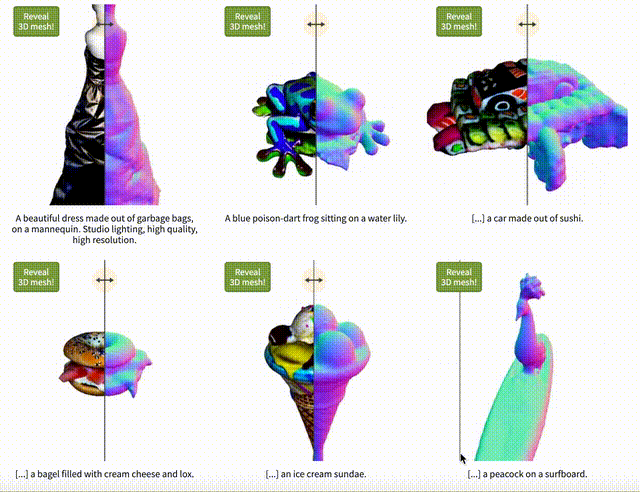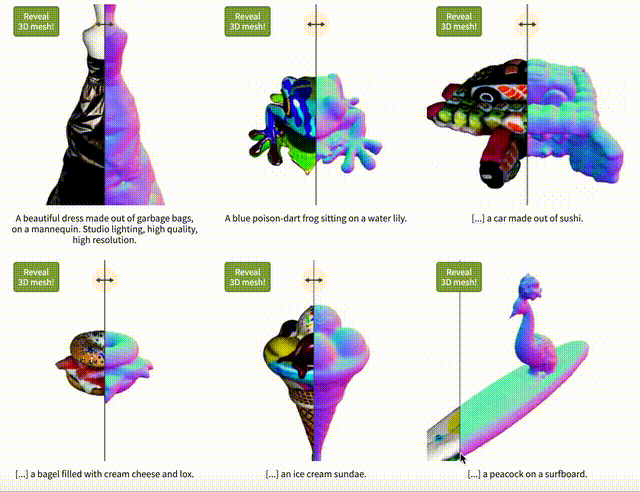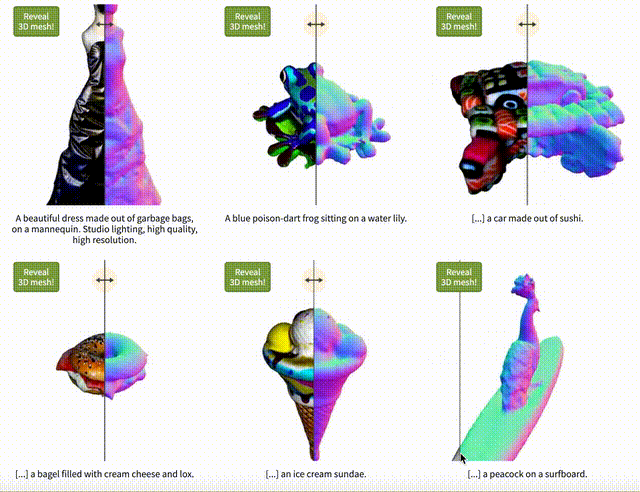
Vitally AI認為Text-to-3D全球都在比較早期的階段, 因為也沒有開源,所以業界無法研究和參與。我們曾經跟其他AI創業者交流,他們用Diffusion Model和Nerf放在一起做實驗,有點樣子,但是最大的障礙還是全球領域能做訓練的3D圖像數據少之又少,而用技術的方法制造AI訓練用的數據成本也很高,我們仍需耐心等候。
09 AI自己玩 Minecraft !?
Minecraft 「我的世界」這個游戲絕對是一個完美的通用智能測試平台,因為:
它是無限開放的,可以提供各種各樣的行為動作。 它具有多種類型的物理和邏輯約束。 它具有許多不同的任務和目標。
2022年我們看到一些實驗室和公司使用Transformer大模型來訓練AI 在Minecraft中執行各種任務的成功案例。這些大模型可以建造城堡,挖掘礦物,甚至與其他玩家交互。

為了利用互聯網上大量可用的未標記視訊數據,OpenAI開發了一種視訊預訓練 (VPT) 算法。首先向游戲商家收集2,000小時的少量數據集,其數據集記錄游戲視訊,也記錄了玩家采取的行動(按鍵操作和鼠標移動)。利用這些數據,訓練出一個逆動力學模型(IDM)以 「預測」 視訊中每個步驟所采取得動作。通過使用經過訓練的 IDM模型來標記更多的在線視訊數據,并通過行為克隆來建立學習的行為。AI通過觀看70,000小時YouTube視訊的大數據量就可以被訓練自己玩Minecraft。
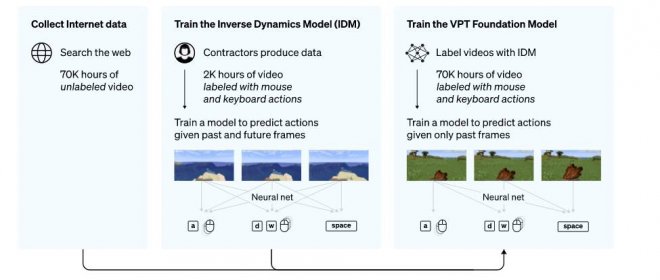
Nvidia還開發了一個名為 MineDojo的AI代理,可以根據 Minecraft中的文字提示執行操作,并獲得了國際機器學習會議的杰出論文獎。微軟也有一個新的AI Minecraft「代理」,它在游戲內運行 。
10 AI 發現新材料
AI在材料科學領域的應用正在快速發展,其中AI發現新材料是一項重要的技術。這項技術包含了數據挖掘和機器學習兩個步驟。數據挖掘通過從大量數據中提取有用信息來實現。AI通過對數據的分析,提取有關材料性能的信息。機器學習是通過利用算法從數據中學習來實現的。在這個步驟中,AI利用算法預測新材料的性能。這個可能更偏向 Analytical AI。
今年,GoogleAI發布了一種名為「Material Discovery」的模型,該模型可以根據給定的物理和化學性質生成新的材料結構。這項技術有望在未來幫助材料科學家發現更高性能的材料。然而,也存在一些挑戰,其中一個是數據缺乏。這項技術需要大量數據來做出準確的預測,如果數據不足,AI可能會做出不準確的預測。另一個挑戰是材料的復雜性。由于材料是復雜的系統,AI可能無法準確預測材料在不同環境中的性能。
11 AI 助力醫學研究
Google旗下公司Deep Mind的AlphaFold (2021) ,是全球第一個能夠準確預測蛋白質3D結構的模型。同年7月,Deep Mind宣布了「蛋白質宇宙」—— 擴大 AlphaFold 的蛋白質數據庫至200M種結構,這簡直是非常珍貴的科學瑰寶!AI在醫學研究領域的應用(AI for Science)也在迅速發展,特別是OpenAI公司的CEO - Sam Altman接下來也非常看好的領域。

2022年GoogleAI發布了一種名為 「MedGPT」 的模型,該模型可以根據病人的病史和影像學數據生成診斷和治療建議。這項技術有望幫助醫生更快更準確地診斷疾病,并且還可以幫助研究人員發現新的治療方法。同年,費城生物醫學工程卓克索大學的一項研究發現,ChatGPT可以通過和人類的對話,幫助發現是否有阿爾茨海默氏病的早期癥狀,準確率達80%,高于使用傳統方法的74.6%的正確率,從而及時提示患病風險。文章前面提到過,GhatGPT的極致能力已經展現在可以通過美國醫療專業執照的考試。
12 AI可以通過網絡視訊學習嗎?——VPT(「視訊預訓練」)模型
AI 可以學習人類復雜的動作嗎?可以!Jeff clune 的團隊發布了VPT(「視訊預訓練」)模型,它甚至可以通過學習自己玩「我的世界」(Minecraft)!在「我的世界」中,一個人制作鉆石工具需要完成2萬多個動作,花費20分鐘,VPT通過學習記錄了人們點擊鍵盤鼠標的操作,居然學會了自己在我的世界中完成這些動作。
換句話說,只要知道了鼠標和鍵盤的點擊移動順序,VPT可以通過Inverse Dynamic Model(逆向動力模型)學習一切我們認為只有人類才能做到的復雜動作,比如如果我們可以準確記錄數字繪畫家在電子屏幕上的操作順序,那麼模型也可以模仿數字繪畫家繪制一幅美麗的日落,VPT為AI通過互聯網上的視訊來學習鋪平了道路!
13 AI 代理在談判上的突破
多年來,人們提出了許多用于外交的人工智能方法,主要依賴手工制定的協議和基于規則的系統,但遠遠落后于人的表現(無論有無溝通)。
Meta公司的人工智能CICERO 是第一個在外交游戲中達到人類水平表現的AI代理,在游戲《外交》中,Cicero具有對他人的信仰、目標和意圖進行推理的能力,可以通過表現同理心、使用人類語言交流并建立人際關系,同時能夠有效地說服甚至欺騙,來達到在游戲中獲勝的目的。
與此同時,DeepMind公司也宣布了他們的外交游戲 AI 代理。試想,如果CICERO與 DeepMind的AI對戰會發生什麼?
14 Music-to-text 音頻生成文本
Whisper 是由OpenAI開發的一個大型開源音頻識別模型。它在英語的語音識別方面達到了接近人類水平的準確性和魯棒性(在語音識別中,「魯棒性」通常指一個模型的能力,即在嘈雜或有干擾的環境下識別語音的準確性和可靠性)。與其他模型不同的是,Whisper使用了更大以及更多樣的訓練數據集。它使用網絡上的共680,000小時的音頻數據進行訓練,這些數據是多語言和多任務的,使得Whisper除了能將英語轉成英文,還能將幾乎所有語種聲音轉成對應文字以及翻譯成英語。
Whisper提供了多種大小的英語/多語言模型,使得開發者能夠在識別速度和識別品質中權衡。對于英語任務,開發者使用較小的模型便可達到良好的效果,識別速度甚至可以達到實時處理的效果。如果使用大模型,識別準確性則可以說超越所有現有商業公司產品。對于漢語任務,開發者必須使用大模型才能達到較準確的識別,識別速度與中國商業公司的產品相比有一定差距。

15 Text-to-music 文本指令生成音樂
MusicLM是由谷歌研究院在近日發布的文本生成音樂模型,只發布了論文與數據集,沒有開源。模型可以從文本描述例如 「平靜的小提琴旋律伴著扭曲的吉他旋律」生成高保真的音樂。MusicLM將文本指示的音樂生成過程描述為一個層次化的序列到序列的建模任務。它生成的音樂頻率為24kHz,在幾分鐘內保持一致。
與之前的模型相比,MusicLM在音頻品質和對文本描述的遵守方面都更優。此外,MusicLM可以以文本描述的旋律為條件,它可以根據文本說明中描述的風格來轉換口哨和哼唱的旋律。為了支持未來的研究,谷歌研究院一并公開發布了MusicCaps。這是一個由5.5K音樂-文本對組成的數據集,有人類專家提供的豐富文本描述。
16 別忘記了亞馬遜云的存在
Amazon SageMaker是在亞馬遜云上的一站式大模型開發平台,可以提高大模型的開發效率。在IDC發布的報告中,Amazon SageMaker被列入「領導者」陣營,并居于圖中最高最遠的位置。
亞馬遜云科技自研AI芯片可以提供更具性價比的方案,例如Amazon Trainium自研芯片的Amazon EC2 Trn1實例可節省高達50%的訓練成本,而Inf2實例可支持橫向擴展分布式推理,方便部署并提升高速推理。
Stability AI選擇AWS作為唯一云服務提供商,在AWS平台上搭建了大規模訓練集群。使用SageMaker Jumpstart預集成的SD2.0預訓練模型和優化庫,Stability AI能夠使其模型訓練具有更高韌性和性能,訓練時間和成本可減少58%(這是很多錢)。

(文章僅代表作者觀點)
[圖擷取自網路,如有疑問請私訊]
|
本篇 |
不想錯過? 請追蹤FB專頁! |
| 喜歡這篇嗎?快分享吧! |








相關文章






科普解密