谷歌報復性砸出5620億參數大模型!機器人都能用,學術圈已刷屏
為應對新一輪技術競賽,谷歌還在不斷出后手。
這兩天,一個名叫 PaLM-E的大模型在AI學術圈瘋狂刷屏。
![]()
它能只需一句話,就讓機器人去廚房抽屜里拿薯片。
![]()
即便是中途干擾它,它也會堅持執行任務。
![]()
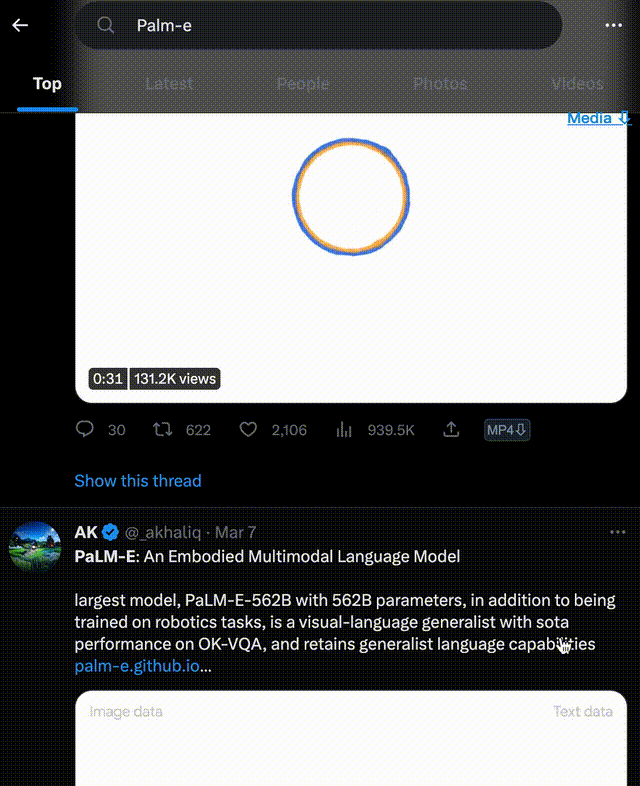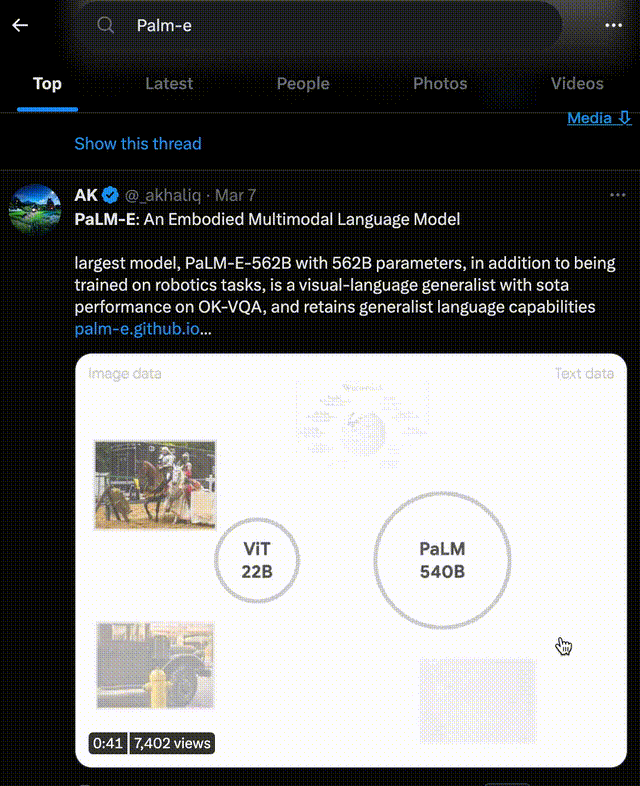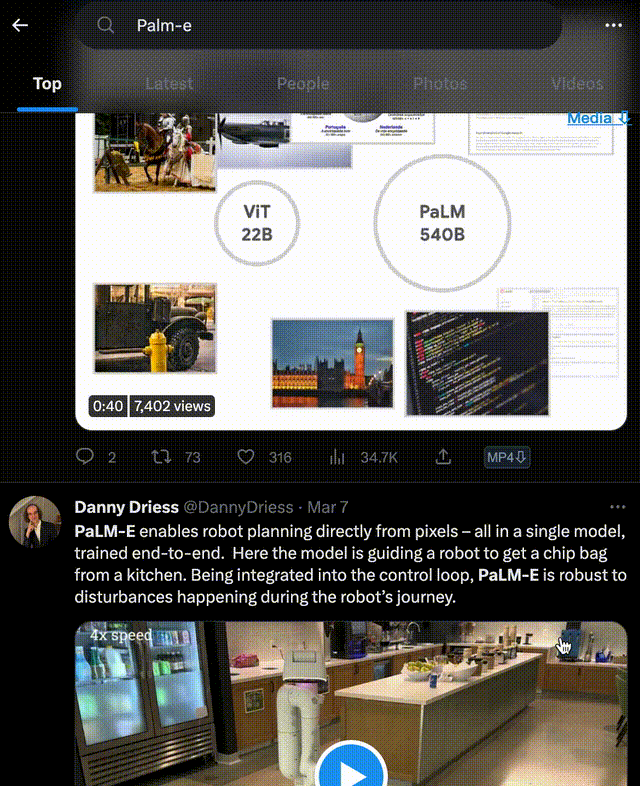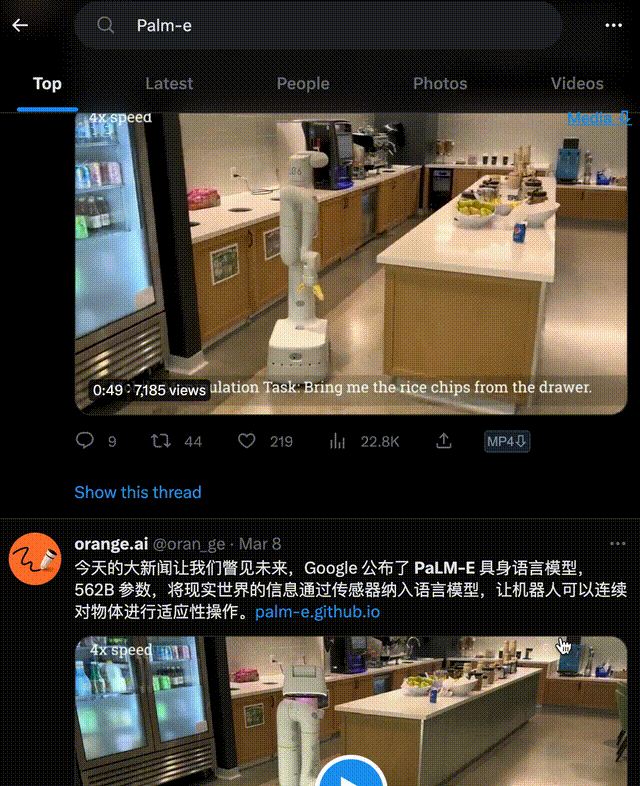
PaLM-E擁有 5620億參數,是GPT-3的三倍多,號稱史上最大規模視覺語言模型。而它背后的打造團隊,正是谷歌和柏林工業大學。
作為一個能處理多模態信息的大模型,它還兼具非常強的邏輯思維。
比如能從一堆圖片里,判斷出哪個是能滾動的。
![]()
還會看圖做算數:
![]()
有人感慨:
這項工作比ChatGPT離AGI更近一步啊!
而另一邊,微軟其實也在嘗試ChatGPT指揮機器人干活。
這麼看,谷歌是憑借PaLM-E一步到位了?
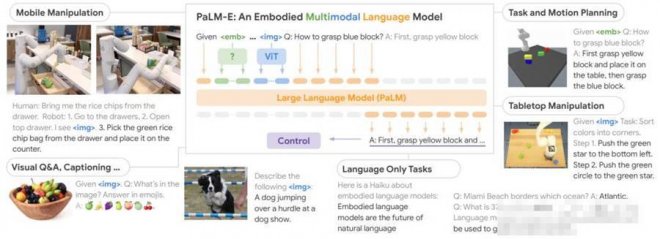
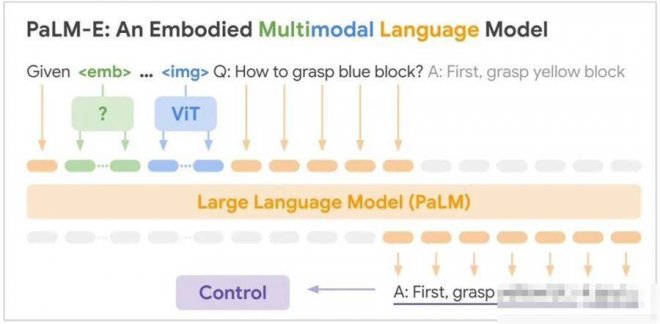
邏輯性更強的大模型PaLM-E是將PaLM和ViT強強聯合。
5620億的參數量,其實就是如上兩個模型參數量相加而來(5400億+220億)。
![]()
PaLM是谷歌在22年發布的語言大模型,它是Pathways架構訓練出來的,能通過「思考過程提示」獲得更準確的邏輯推理能力,減少AI生成內容中的錯誤和胡言亂語。
Pathways是一種稀疏模型架構,是谷歌AI這兩年重點發展方向之一,目標就是訓練出可執行成千上百種任務的通用模型。
ViT是計算機視覺領域的經典工作了,即Vision Transformer。
兩者結合后,PaLM-E可以處理多模態信息。包括:
語言 圖像 場景表征 物體表征
通過加一個編碼器,模型可以將圖像或傳感器數據編碼為一系列與語言標記大小相同的向量,將此作為輸入用于下一個token預測,進行端到端訓練。
![]()
具體能力方面,PaLM-E表現出了比較強的邏輯性。
比如給它一張圖片,然后讓它根據所看到的做出蛋糕。
模型能先判斷出圖像中都有什麼,然后分成9步講了該如何制作蛋糕,從最初的磕雞蛋到最后洗碗都包括在內。
![]()
有人還調侃說,這機器人怎麼在把蛋糕給我前先自己吃了?
還有根據圖片做判斷:我能在這條路上騎腳踏車嗎?
模型進行一系列邏輯推斷:
1、不能進入2、除了腳踏車3、除了腳踏車以外都不能進入4、答案是可以
![]()
這和人類思考的過程確實很像了。
不僅如此,模型的最強大之處在于,它無需經過預處理,即提前理解環境。
它做出判斷和回答,完全是基于它自己的「經驗」。
研究人員表示,這項成果表現出了很強的 正向遷移(positive transfer)能力。
在多個領域任務的訓練中,PaLM-E的表現都優于單項任務機器人模型。
![]()
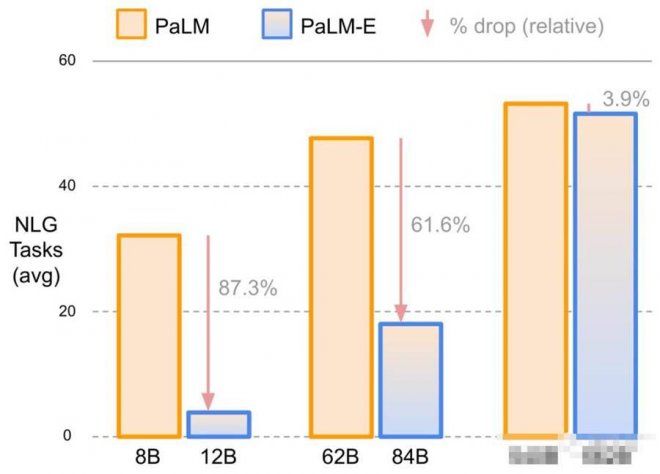
而且他們還發現,語言模型的規模越大,它最終能保持的語言理解能力越強。
比如使用5400億參數規模的PaLM時,PaLM-E在語言任務上的實際能力僅下降了3.9%。
![]()
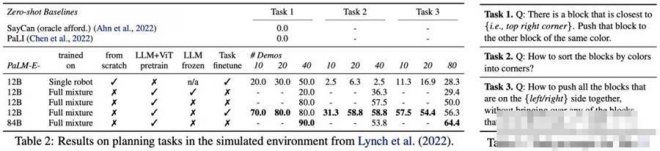
從實驗結果來看,PaLM-E在OK-VQA基準上達到新SOTA。
![]()
在模擬環境下的任務完成度也都不錯。
![]()
再次驗證大力出奇跡目前這項研究已引發非常廣泛的討論。
主要在于以下幾個方面:
1、一定程度上驗證了「大力出奇跡」2、比ChatGPT更接近AGI?
一方面,作為目前已知的規模最大的視覺語言模型,PaLM-E的表現已經足夠驚艷了。
去年,DeepMind也發布過一個通才大模型Gota,在604個不同的任務上接受了訓練。
但當時有很多人認為它并不算真正意義上的通用,因為研究無法證明模型在不同任務之間發生了正向遷移。
論文作者表示,這或許是因為模型規模還不夠大。
如今,PaLM-E似乎完成了這一論證。
![]()
不過也有聲音擔心,這是不是把卷參數從NLP引到了CV圈?
另一方面,是從大趨勢上來看。
有人表示,這項工作看上去要 比ChatGPT更接近AGI啊。
的確,用ChatGPT還只是提供文字建議,很多具體動手的事還要自己來。
但PaLM-E屬于把大模型能力拉入到具象化層面,AI和物理世界之間的結界要被打破了。
![]()
而且這個趨勢顯然也是大家都在琢磨的,微軟前不久也發布了一項非常相似的工作——讓ChatGPT指揮機器人。
除此之外,還有很多人表示,這再一次驗證了多模態是未來。
不過,這項成果現在只有論文和demo發布,真正能力有待驗證。
![]()
此外還有人發現,模型驅動的機器人,背后的開發團隊在幾周前被谷歌一鍋端了。。。
![]()
所以關于PaLM-E的更多后續,咱們還得再蹲蹲看。
[圖擷取自網路,如有疑問請私訊]
這兩天,一個名叫 PaLM-E的大模型在AI學術圈瘋狂刷屏。
它能只需一句話,就讓機器人去廚房抽屜里拿薯片。

即便是中途干擾它,它也會堅持執行任務。

PaLM-E擁有 5620億參數,是GPT-3的三倍多,號稱史上最大規模視覺語言模型。而它背后的打造團隊,正是谷歌和柏林工業大學。
作為一個能處理多模態信息的大模型,它還兼具非常強的邏輯思維。
比如能從一堆圖片里,判斷出哪個是能滾動的。

還會看圖做算數:

有人感慨:
這項工作比ChatGPT離AGI更近一步啊!
而另一邊,微軟其實也在嘗試ChatGPT指揮機器人干活。
這麼看,谷歌是憑借PaLM-E一步到位了?
邏輯性更強的大模型PaLM-E是將PaLM和ViT強強聯合。
5620億的參數量,其實就是如上兩個模型參數量相加而來(5400億+220億)。
PaLM是谷歌在22年發布的語言大模型,它是Pathways架構訓練出來的,能通過「思考過程提示」獲得更準確的邏輯推理能力,減少AI生成內容中的錯誤和胡言亂語。
Pathways是一種稀疏模型架構,是谷歌AI這兩年重點發展方向之一,目標就是訓練出可執行成千上百種任務的通用模型。
ViT是計算機視覺領域的經典工作了,即Vision Transformer。
兩者結合后,PaLM-E可以處理多模態信息。包括:
語言 圖像 場景表征 物體表征
通過加一個編碼器,模型可以將圖像或傳感器數據編碼為一系列與語言標記大小相同的向量,將此作為輸入用于下一個token預測,進行端到端訓練。
具體能力方面,PaLM-E表現出了比較強的邏輯性。
比如給它一張圖片,然后讓它根據所看到的做出蛋糕。
模型能先判斷出圖像中都有什麼,然后分成9步講了該如何制作蛋糕,從最初的磕雞蛋到最后洗碗都包括在內。
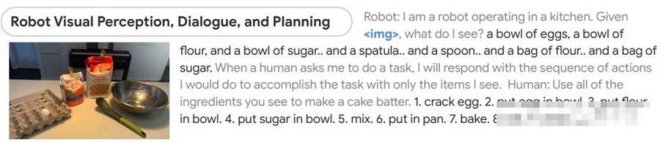
有人還調侃說,這機器人怎麼在把蛋糕給我前先自己吃了?
還有根據圖片做判斷:我能在這條路上騎腳踏車嗎?
模型進行一系列邏輯推斷:
1、不能進入2、除了腳踏車3、除了腳踏車以外都不能進入4、答案是可以

這和人類思考的過程確實很像了。
不僅如此,模型的最強大之處在于,它無需經過預處理,即提前理解環境。
它做出判斷和回答,完全是基于它自己的「經驗」。
研究人員表示,這項成果表現出了很強的 正向遷移(positive transfer)能力。
在多個領域任務的訓練中,PaLM-E的表現都優于單項任務機器人模型。
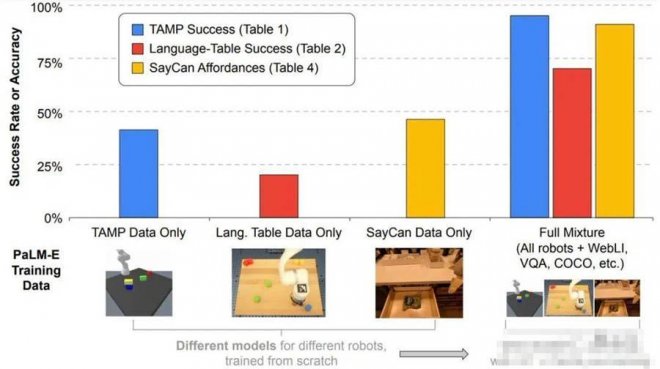
而且他們還發現,語言模型的規模越大,它最終能保持的語言理解能力越強。
比如使用5400億參數規模的PaLM時,PaLM-E在語言任務上的實際能力僅下降了3.9%。
從實驗結果來看,PaLM-E在OK-VQA基準上達到新SOTA。

在模擬環境下的任務完成度也都不錯。
再次驗證大力出奇跡目前這項研究已引發非常廣泛的討論。
主要在于以下幾個方面:
1、一定程度上驗證了「大力出奇跡」2、比ChatGPT更接近AGI?
一方面,作為目前已知的規模最大的視覺語言模型,PaLM-E的表現已經足夠驚艷了。
去年,DeepMind也發布過一個通才大模型Gota,在604個不同的任務上接受了訓練。
但當時有很多人認為它并不算真正意義上的通用,因為研究無法證明模型在不同任務之間發生了正向遷移。
論文作者表示,這或許是因為模型規模還不夠大。
如今,PaLM-E似乎完成了這一論證。

不過也有聲音擔心,這是不是把卷參數從NLP引到了CV圈?
另一方面,是從大趨勢上來看。
有人表示,這項工作看上去要 比ChatGPT更接近AGI啊。
的確,用ChatGPT還只是提供文字建議,很多具體動手的事還要自己來。
但PaLM-E屬于把大模型能力拉入到具象化層面,AI和物理世界之間的結界要被打破了。

而且這個趨勢顯然也是大家都在琢磨的,微軟前不久也發布了一項非常相似的工作——讓ChatGPT指揮機器人。
除此之外,還有很多人表示,這再一次驗證了多模態是未來。
不過,這項成果現在只有論文和demo發布,真正能力有待驗證。
此外還有人發現,模型驅動的機器人,背后的開發團隊在幾周前被谷歌一鍋端了。。。
所以關于PaLM-E的更多后續,咱們還得再蹲蹲看。
[圖擷取自網路,如有疑問請私訊]
|
本篇 |
不想錯過? 請追蹤FB專頁! |
| 喜歡這篇嗎?快分享吧! |








相關文章






科普解密