
谷歌實現量子計算糾錯大突破!成果登上Nature,號稱第二大里程碑
量子計算領域的新里程碑,來了!
谷歌科學家證明, 通過增加量子比特的數量,就能降低量子計算的錯誤率。
研究成果登上最新一期《Nature》。
![]()
結果顯示,在72個量子位的超導量子處理器上:
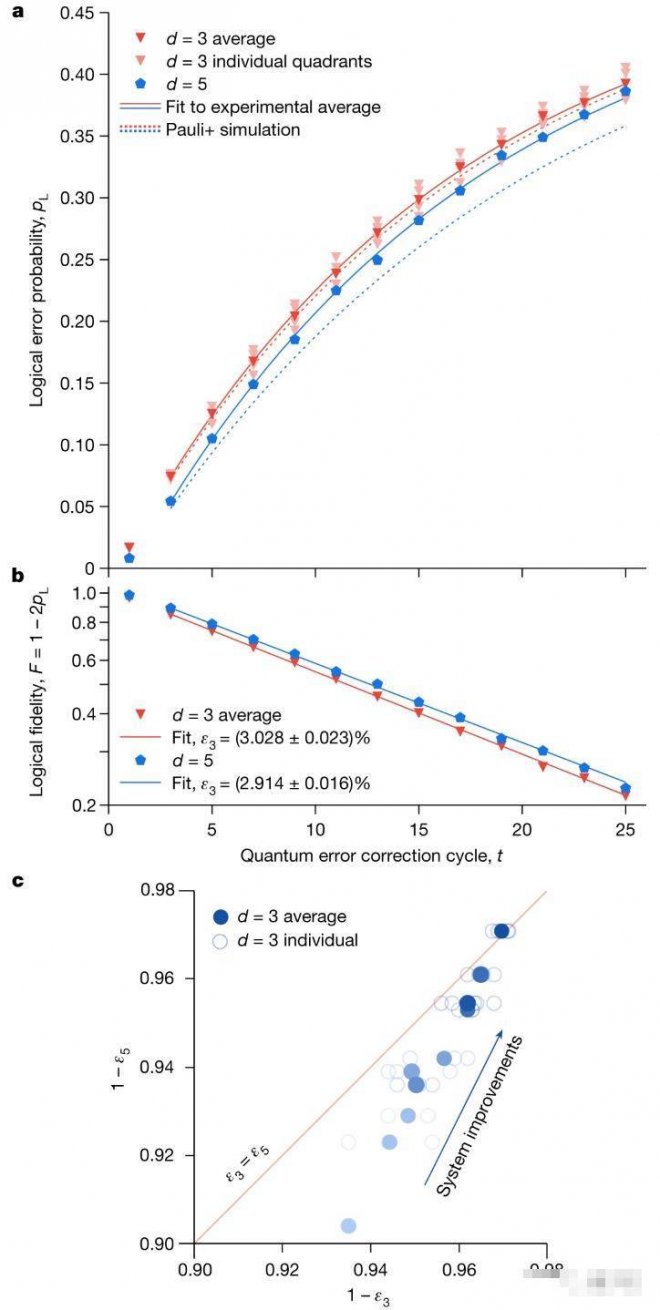
distance-5邏輯量子位(基于49個物理量子比特),每周期的邏輯錯誤為2.914%。 distance-3邏輯量子位(基于17個物理量子比特),每周期的邏輯錯誤為3.028%。
可以發現前者的量子比特多了,但是錯誤率卻降低了。
要知道,量子計算糾錯是量子計算發展的關鍵一步。過去提出的理論方案中,需要引入更多量子比特,這會導致量子計算出錯的源頭增多。
谷歌量子計算部門負責人表示,盡管他們的方法只能將錯誤率降低一點,但這意味著谷歌已經突破了「平衡點」。
我們需要讓它降更多。
抑制量子誤差量子計算機一直被視為可以解決普通計算機所無法勝任的超大規模計算,如將大量整數分解為質數、模擬復雜化學反應等。
但是和普通計算機一樣,量子計算機很容易出現底層物理系統「噪聲」引起的錯誤。
對于普通計算機,通過比特(可以表示0或1)來存儲信息,并將部分信息復制到冗余的「糾錯」比特上。當出現錯誤時,比如雜散電子穿過了絕緣屏障,或者宇宙射線干擾了電路,芯片就能自動發現問題并修復。
但是,量子計算機是在量子比特上運算,量子比特可以被設置為0、1,或者同時設置為0和1的任意混合,比如30%的0和70%的1。
這意味著量子比特不能被讀出,否則它的量子狀態將會丟失。由此,量子計算機不能像普通計算機那樣,簡單地將部分信息復制到冗余量子比特上。
![]()
理論物理學家們提出了一種解決辦法: 量子誤差糾正。
邏輯量子比特由此而來。它是由物理量子比特組成的集合,它們共同工作以執行計算。
然后機器就可以使用一些物理量子比特來檢查邏輯量子比特的情況,并糾正錯誤。
物理量子比特越多,就能越好地抑制錯誤。
(量子比特有許多物理實現,在傳統計算機使用硅基芯片的地方,量子比特可以由捕獲的離子、光子、人造原子或真實原子、準粒子組成)
但量子比特是量子計算出錯的源頭,增加更多量子比特,意味著出現錯誤的可能也會增加。
因此必須要將出錯的「密度」降低。
谷歌研究人員提出了一種具有 超導量子比特的表面碼。
表面碼是一組量子糾錯碼。它將邏輯量子比特編碼為物理量子比特的d × d平方的聯合糾纏態,稱為數據量子比特。
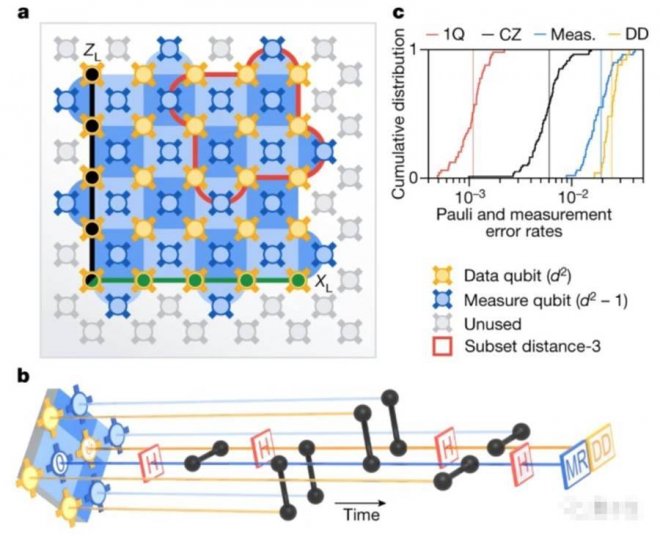
邏輯量子位狀態由一對反交換邏輯可觀測量X˪和Z˪定義,如下圖a表示,是一個72量子比特的Sycamore量子計算機原理圖。
其中嵌入了distance-5的表面編碼,由25個數據量子比特(黃色)和24個測量量子比特(藍色)組成。
每個測量量子比特和一個穩定器(stabilizer,藍色方塊)相關聯,邏輯運算符Z˪和X˪遍歷數組,在左下角的數據量子比特相交。
右上角的紅色框的象限,是4個distance-3表面碼的子集之一,這是和distance-5表面碼作比較的對照。
![]()
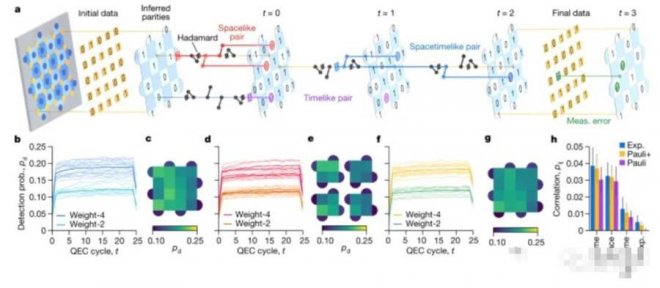
為了檢測錯誤,會周期性地測量相鄰數據量子比特簇的X和Z奇偶校驗。
如圖b所示,每個測量量子比特都和相鄰的數據量子比特相互作用,將聯合數據量子位奇偶校驗映射到測量量子位狀態,然后測量量子位狀態。
每個奇偶校驗量或穩定器,都與編碼的量子比特的邏輯觀測值以及其他穩定器交換。
因此,可以在奇偶校驗測量發生意外變化時檢測到錯誤,并不會干擾邏輯量子比特的狀態。
![]()
通過如上方法,谷歌研究人員建造了一個72個量子比特的超導量子處理器,用兩種不同的表面碼做了測試。
結果表明,較大表面碼能展現出個更好的邏輯量子比特性能,即錯誤率更低。如下紅藍線對比:
![]()
量子計算到哪一步了?這一成就也被谷歌視為實現量子優越后的又一重大突破。
按照谷歌自己的「六步走」規劃,實現量子優勢是第一步,降低量子計算錯誤率是第二步,最終要實現建造一台由100萬個物理量子比特組成的量子計算機,能編碼1000個邏輯量子比特。
他們表示,等到這一步實現,量子計算的商業價值也就能實現了。
除此之外,他們還表示超導量子比特只是構建量子計算機的幾種方法之一,但這種方法最有可能成功。但如果發現了新方法更有效,他們會馬上調整方向。
中國對于量子計算的發展步驟也提出了明確的規劃。
中科院院士潘建偉提出,量子計算分為三個發展階段:
實現量子計算優越 實現專用的量子模擬機,可應用于組合優化量子化學、機器學習等特定問題 在實現量子糾錯的基礎上,構建可編程通用量子計算機
目前,中美加已實現了量子計算優越。
達到專用的量子計算模擬機,潘院士估計還需5-10年,是當前學術界的主要研究任務。
[圖擷取自網路,如有疑問請私訊]
谷歌科學家證明, 通過增加量子比特的數量,就能降低量子計算的錯誤率。
研究成果登上最新一期《Nature》。

結果顯示,在72個量子位的超導量子處理器上:
distance-5邏輯量子位(基于49個物理量子比特),每周期的邏輯錯誤為2.914%。 distance-3邏輯量子位(基于17個物理量子比特),每周期的邏輯錯誤為3.028%。
可以發現前者的量子比特多了,但是錯誤率卻降低了。
要知道,量子計算糾錯是量子計算發展的關鍵一步。過去提出的理論方案中,需要引入更多量子比特,這會導致量子計算出錯的源頭增多。
谷歌量子計算部門負責人表示,盡管他們的方法只能將錯誤率降低一點,但這意味著谷歌已經突破了「平衡點」。
我們需要讓它降更多。
抑制量子誤差量子計算機一直被視為可以解決普通計算機所無法勝任的超大規模計算,如將大量整數分解為質數、模擬復雜化學反應等。
但是和普通計算機一樣,量子計算機很容易出現底層物理系統「噪聲」引起的錯誤。
對于普通計算機,通過比特(可以表示0或1)來存儲信息,并將部分信息復制到冗余的「糾錯」比特上。當出現錯誤時,比如雜散電子穿過了絕緣屏障,或者宇宙射線干擾了電路,芯片就能自動發現問題并修復。
但是,量子計算機是在量子比特上運算,量子比特可以被設置為0、1,或者同時設置為0和1的任意混合,比如30%的0和70%的1。
這意味著量子比特不能被讀出,否則它的量子狀態將會丟失。由此,量子計算機不能像普通計算機那樣,簡單地將部分信息復制到冗余量子比特上。

理論物理學家們提出了一種解決辦法: 量子誤差糾正。
邏輯量子比特由此而來。它是由物理量子比特組成的集合,它們共同工作以執行計算。
然后機器就可以使用一些物理量子比特來檢查邏輯量子比特的情況,并糾正錯誤。
物理量子比特越多,就能越好地抑制錯誤。
(量子比特有許多物理實現,在傳統計算機使用硅基芯片的地方,量子比特可以由捕獲的離子、光子、人造原子或真實原子、準粒子組成)
但量子比特是量子計算出錯的源頭,增加更多量子比特,意味著出現錯誤的可能也會增加。
因此必須要將出錯的「密度」降低。
谷歌研究人員提出了一種具有 超導量子比特的表面碼。
表面碼是一組量子糾錯碼。它將邏輯量子比特編碼為物理量子比特的d × d平方的聯合糾纏態,稱為數據量子比特。
邏輯量子位狀態由一對反交換邏輯可觀測量X˪和Z˪定義,如下圖a表示,是一個72量子比特的Sycamore量子計算機原理圖。
其中嵌入了distance-5的表面編碼,由25個數據量子比特(黃色)和24個測量量子比特(藍色)組成。
每個測量量子比特和一個穩定器(stabilizer,藍色方塊)相關聯,邏輯運算符Z˪和X˪遍歷數組,在左下角的數據量子比特相交。
右上角的紅色框的象限,是4個distance-3表面碼的子集之一,這是和distance-5表面碼作比較的對照。
為了檢測錯誤,會周期性地測量相鄰數據量子比特簇的X和Z奇偶校驗。
如圖b所示,每個測量量子比特都和相鄰的數據量子比特相互作用,將聯合數據量子位奇偶校驗映射到測量量子位狀態,然后測量量子位狀態。
每個奇偶校驗量或穩定器,都與編碼的量子比特的邏輯觀測值以及其他穩定器交換。
因此,可以在奇偶校驗測量發生意外變化時檢測到錯誤,并不會干擾邏輯量子比特的狀態。
通過如上方法,谷歌研究人員建造了一個72個量子比特的超導量子處理器,用兩種不同的表面碼做了測試。
結果表明,較大表面碼能展現出個更好的邏輯量子比特性能,即錯誤率更低。如下紅藍線對比:
量子計算到哪一步了?這一成就也被谷歌視為實現量子優越后的又一重大突破。
按照谷歌自己的「六步走」規劃,實現量子優勢是第一步,降低量子計算錯誤率是第二步,最終要實現建造一台由100萬個物理量子比特組成的量子計算機,能編碼1000個邏輯量子比特。
他們表示,等到這一步實現,量子計算的商業價值也就能實現了。
除此之外,他們還表示超導量子比特只是構建量子計算機的幾種方法之一,但這種方法最有可能成功。但如果發現了新方法更有效,他們會馬上調整方向。
中國對于量子計算的發展步驟也提出了明確的規劃。
中科院院士潘建偉提出,量子計算分為三個發展階段:
實現量子計算優越 實現專用的量子模擬機,可應用于組合優化量子化學、機器學習等特定問題 在實現量子糾錯的基礎上,構建可編程通用量子計算機
目前,中美加已實現了量子計算優越。
達到專用的量子計算模擬機,潘院士估計還需5-10年,是當前學術界的主要研究任務。
[圖擷取自網路,如有疑問請私訊]
|
本篇 |
不想錯過? 請追蹤FB專頁! |
| 喜歡這篇嗎?快分享吧! |








相關文章





科普解密








