首次發現!數據異構影響聯邦學習模型,關鍵在于表征維度坍縮
隨著深度學習大獲成功,保護用戶數據隱私變得越來越重要。
聯邦學習(Federated Learning)應運而生,這是一種基于隱私保護的分布式機器學習框架。
它可以讓原始數據保留在本地,讓多方聯合共享模型訓練。
![]()
但它有一個問題—— 數據的異質化(data heterogeneity),即不同的參與方的本地數據來自不同的分布,這將嚴重影響全局模型的最終性能,背后原因也十分復雜。
字節跳動、新加坡國立大學及中科院自動化所的學者們 首次發現了關鍵影響因素。
即:數據異質化導致了表征的 維度坍縮(dimensional collapse),由此大大限制了模型的表達能力,影響了最終全局模型的性能。
為了緩解這一問題,研究人員提出了一個新聯邦學習正則項: FedDecorr。
![]()
結果表明,使用該方法后,數據異質化帶來的維度坍縮問題被有效緩解,顯著提升模型在該場景下的性能。
同時這一方法實現簡單,幾乎不會帶來額外計算負擔,可以很容易地加入到多種聯邦學習算法上。
如何影響?觀察一:更嚴重的數據異質化會為全局模型(global model)帶來更嚴重的維度坍縮首先,為了更好地理解數據異質化是如何影響全局模型輸出表征的,研究人員探索了隨著數據異質化越來越嚴重, 全局模型輸出表征是如何而變化的。
基于模型輸出的表征,估計其表征分布的協方差矩陣(covariance matrix),并且按照從大到小的順序可視化了該協方差矩陣的特征值。結果如下圖所示。α越小,異質化程度越高,α為正無窮時為同質化場景。k為特征值的index。
![]()
對于該曲線,如果特征值大部分相對較大,即意味著表征能夠更加均勻地分布在不同的特征方向上。而如果該曲線只有前面少數特征值較大,而后面大部分特征值都很小,就意味著表征分布被壓縮在少數特征方向上,即維度坍縮現象。
因此,從圖中可以看到, 隨著數據異質化程度越來越高(α越來越小),維度坍縮的現象就越來越嚴重。
觀察二:全局模型的維度坍縮來自聯邦參與各方的局部模型的維度坍縮由于全局模型是聯邦參與各方的局部模型融合的結果,因此作者推斷:全局模型的維度坍縮來源于聯邦參與各方的局部模型的維度坍縮。
為了進一步驗證該推斷,作者使用與觀察1類似的方法,針對不同程度數據異質化場景下得到的局部模型進行了可視化。結果如下圖所示。
![]()
從圖中可以看到,對于局部模型,隨著數據異質化程度的提升,維度坍縮的現象也越來越嚴重。因此得出結論, 全局模型的維度坍縮來源于聯邦參與各方的局部模型的維度坍縮。
怎麼解決?受到以上兩個觀察的啟發,由于全局模型的維度坍縮來源于本地局部模型的維度坍縮,研究人員提出在本地訓練階段來解決聯邦學習中的表征維度坍縮問題。
首先,一個最直觀的可用的正則項為以下形式:
![]()
其中
![]()
為第
![]()
個特征值。該正則項將約束特征值之間的方差變小,從而使得較小的特征值不會偏向于0,由此緩解維度坍縮。
然而,直接計算特征值往往會帶來數值不穩定,計算時間較長等問題。因此借助以下proposition來改進方法。
為了方便處理,需要對表征向量做z-score歸一化。這將使得協方差矩陣變成相關系數矩陣(對角線元素都是1)。
基于這個背景,可以得到以下proposition:
![]()
這一proposition意味著,原本較為復雜的基于特征值的正則化項,可以被轉化為以下易于實現且計算方便的目標:
![]()
該正則項即是簡單的約束表征的相關系數矩陣的Frobenius norm更小。研究人員將該方法命名為 FedDecorr。
因此,對于每個聯邦學習參與方,本地的優化目標為:
![]()
其中
![]()
為分類的交叉熵損失函數,β為一個超參數,即FedDecorr正則項的系數。
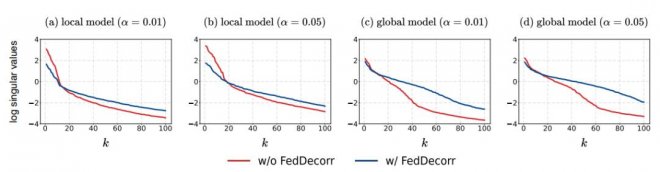
實驗結果首先,驗證使用FedDecorr是否可以有效緩解維度坍縮。
在α=0.01/0.05這兩個強數據異質化的場景下,觀察使用FedDecorr對模型輸出表征的影響。
結果如下圖所示。
![]()
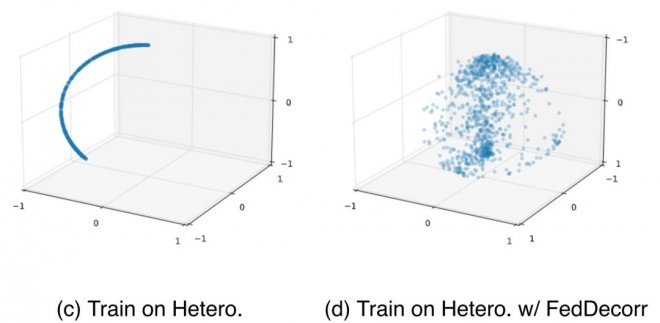
可以看到,使用FedDecorr可以有效地緩解本地局部模型的維度坍縮,從而進一步緩解全局模型的維度坍縮。
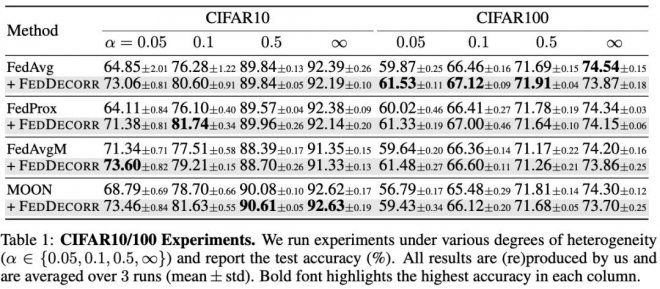
在CIFAR10/100兩個數據集上驗證方法。研究團隊發現FedDecorr可以很方便的加入到之前提出的多個聯邦學習方法,并且帶來顯著提升:
![]()
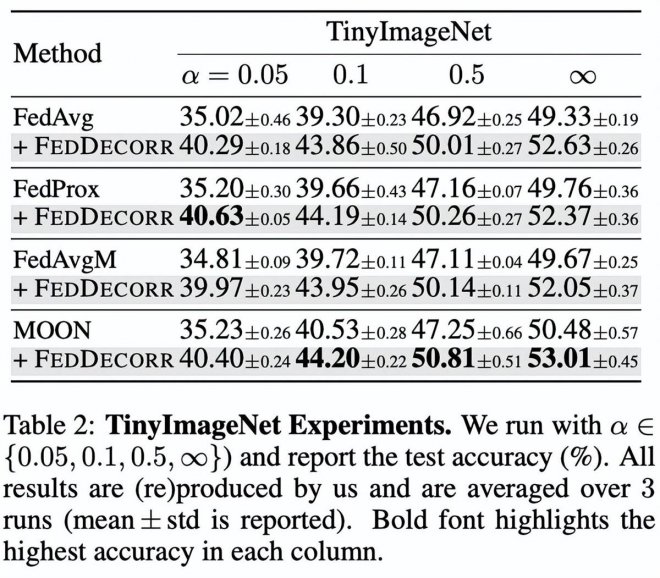
同時,為了展示方法的可擴展性,作者在較大規模數據集(TinyImageNet)上進行了實驗,并且也觀察到了顯著提升:
![]()
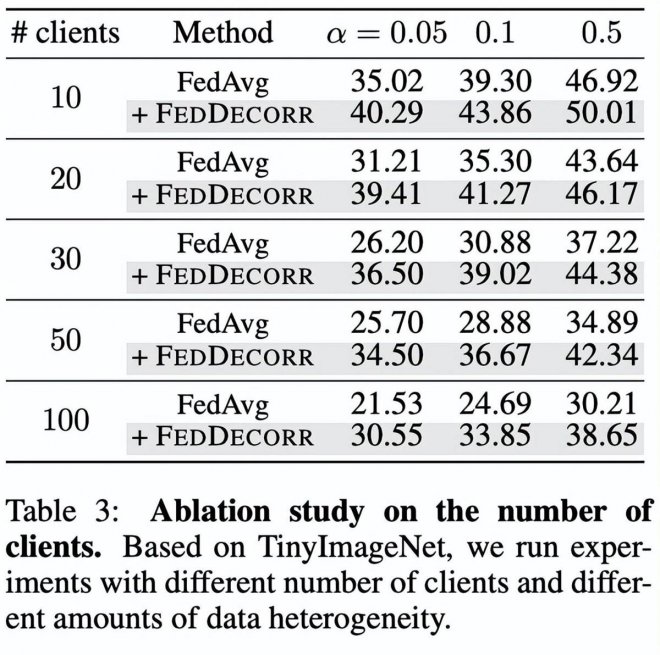
此外還基于TinyImageNet,驗證了FedDecorr在更大規模聯邦參與方的場景下的有效性。
結果如下表。通過實驗結果展示了FedDecorr可以被用于較大規模聯邦參與方的場景。
![]()
FedDecorr對正則項系數(超參數β)的魯棒性結果如下圖所示。
![]()
通過實驗,發現FedDecorr對于其超參數β有較強的魯棒性。
同時發現將β設為0.1是一個不錯的默認值。
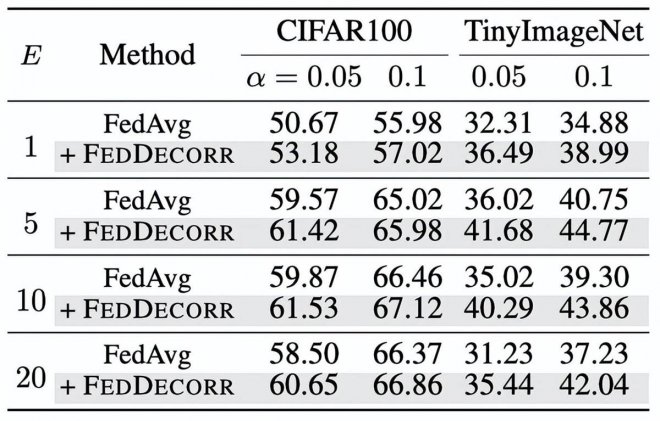
最后,研究人員驗證了在聯邦學習時,使用不同的local epoch下FedDecorr也可以帶來普遍的提升:
![]()
[圖擷取自網路,如有疑問請私訊]
聯邦學習(Federated Learning)應運而生,這是一種基于隱私保護的分布式機器學習框架。
它可以讓原始數據保留在本地,讓多方聯合共享模型訓練。

但它有一個問題—— 數據的異質化(data heterogeneity),即不同的參與方的本地數據來自不同的分布,這將嚴重影響全局模型的最終性能,背后原因也十分復雜。
字節跳動、新加坡國立大學及中科院自動化所的學者們 首次發現了關鍵影響因素。
即:數據異質化導致了表征的 維度坍縮(dimensional collapse),由此大大限制了模型的表達能力,影響了最終全局模型的性能。
為了緩解這一問題,研究人員提出了一個新聯邦學習正則項: FedDecorr。
結果表明,使用該方法后,數據異質化帶來的維度坍縮問題被有效緩解,顯著提升模型在該場景下的性能。
同時這一方法實現簡單,幾乎不會帶來額外計算負擔,可以很容易地加入到多種聯邦學習算法上。
如何影響?觀察一:更嚴重的數據異質化會為全局模型(global model)帶來更嚴重的維度坍縮首先,為了更好地理解數據異質化是如何影響全局模型輸出表征的,研究人員探索了隨著數據異質化越來越嚴重, 全局模型輸出表征是如何而變化的。
基于模型輸出的表征,估計其表征分布的協方差矩陣(covariance matrix),并且按照從大到小的順序可視化了該協方差矩陣的特征值。結果如下圖所示。α越小,異質化程度越高,α為正無窮時為同質化場景。k為特征值的index。
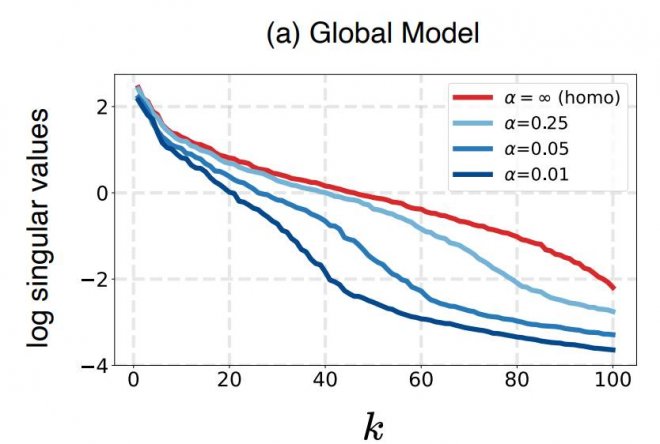
對于該曲線,如果特征值大部分相對較大,即意味著表征能夠更加均勻地分布在不同的特征方向上。而如果該曲線只有前面少數特征值較大,而后面大部分特征值都很小,就意味著表征分布被壓縮在少數特征方向上,即維度坍縮現象。
因此,從圖中可以看到, 隨著數據異質化程度越來越高(α越來越小),維度坍縮的現象就越來越嚴重。
觀察二:全局模型的維度坍縮來自聯邦參與各方的局部模型的維度坍縮由于全局模型是聯邦參與各方的局部模型融合的結果,因此作者推斷:全局模型的維度坍縮來源于聯邦參與各方的局部模型的維度坍縮。
為了進一步驗證該推斷,作者使用與觀察1類似的方法,針對不同程度數據異質化場景下得到的局部模型進行了可視化。結果如下圖所示。
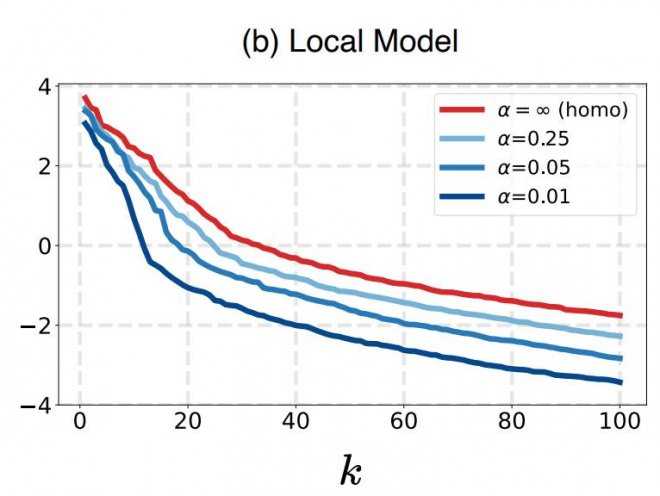
從圖中可以看到,對于局部模型,隨著數據異質化程度的提升,維度坍縮的現象也越來越嚴重。因此得出結論, 全局模型的維度坍縮來源于聯邦參與各方的局部模型的維度坍縮。
怎麼解決?受到以上兩個觀察的啟發,由于全局模型的維度坍縮來源于本地局部模型的維度坍縮,研究人員提出在本地訓練階段來解決聯邦學習中的表征維度坍縮問題。
首先,一個最直觀的可用的正則項為以下形式:
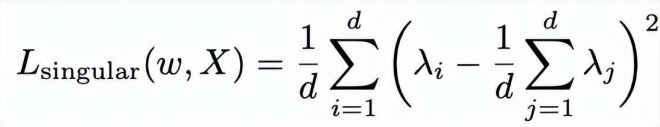
其中
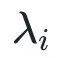
為第
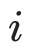
個特征值。該正則項將約束特征值之間的方差變小,從而使得較小的特征值不會偏向于0,由此緩解維度坍縮。
然而,直接計算特征值往往會帶來數值不穩定,計算時間較長等問題。因此借助以下proposition來改進方法。
為了方便處理,需要對表征向量做z-score歸一化。這將使得協方差矩陣變成相關系數矩陣(對角線元素都是1)。
基于這個背景,可以得到以下proposition:
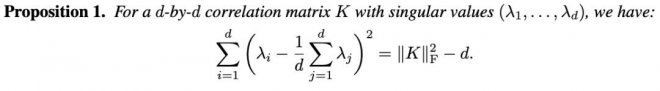
這一proposition意味著,原本較為復雜的基于特征值的正則化項,可以被轉化為以下易于實現且計算方便的目標:
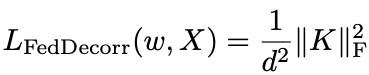
該正則項即是簡單的約束表征的相關系數矩陣的Frobenius norm更小。研究人員將該方法命名為 FedDecorr。
因此,對于每個聯邦學習參與方,本地的優化目標為:
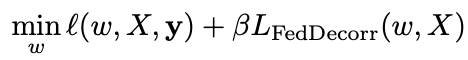
其中
為分類的交叉熵損失函數,β為一個超參數,即FedDecorr正則項的系數。
實驗結果首先,驗證使用FedDecorr是否可以有效緩解維度坍縮。
在α=0.01/0.05這兩個強數據異質化的場景下,觀察使用FedDecorr對模型輸出表征的影響。
結果如下圖所示。
可以看到,使用FedDecorr可以有效地緩解本地局部模型的維度坍縮,從而進一步緩解全局模型的維度坍縮。
在CIFAR10/100兩個數據集上驗證方法。研究團隊發現FedDecorr可以很方便的加入到之前提出的多個聯邦學習方法,并且帶來顯著提升:
同時,為了展示方法的可擴展性,作者在較大規模數據集(TinyImageNet)上進行了實驗,并且也觀察到了顯著提升:
此外還基于TinyImageNet,驗證了FedDecorr在更大規模聯邦參與方的場景下的有效性。
結果如下表。通過實驗結果展示了FedDecorr可以被用于較大規模聯邦參與方的場景。
FedDecorr對正則項系數(超參數β)的魯棒性結果如下圖所示。
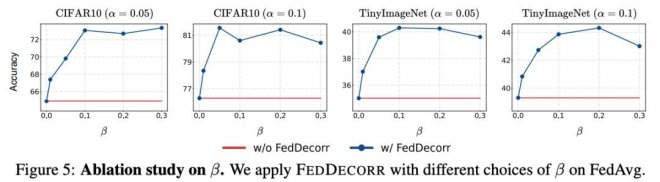
通過實驗,發現FedDecorr對于其超參數β有較強的魯棒性。
同時發現將β設為0.1是一個不錯的默認值。
最后,研究人員驗證了在聯邦學習時,使用不同的local epoch下FedDecorr也可以帶來普遍的提升:
[圖擷取自網路,如有疑問請私訊]
|
本篇 |
不想錯過? 請追蹤FB專頁! |
| 喜歡這篇嗎?快分享吧! |








相關文章





科普解密