Prompt Engineering全面自動化:LeCun看了沉默,ChatGPT直呼內行
在計算機領域,提示詞 (Prompt) 指的是算法輸出之前的那段前置左向字符串。比如最早 MSDOS 下的 C:>,Linux 下的~:,IPython 下面的 >>> 這些都算是提示詞。在 2023 年,提示詞已經成為和大規模語言模型 (LLMs) 互動最自然直觀的方式。
![]()
如果將 ChatGPT 比喻成哈利波特小說中的絢麗魔法,那麼提示詞就像召喚魔法時的咒語。 能不能用好這個魔法,取決于你念咒語時是清晰明確,還是夾雜著 「口音」。 同樣一個魔法,念咒的人不同,威力也不盡相同。所謂一千個讀者就有一千個哈姆雷特,但一千個巫師的阿瓦達索命咒也不及伏地魔一個人念的有效(當然伏地魔念得再好也不如哈利念得有效)。
所以,能不能用好 ChatGPT 和大規模語言模型,很大程度上取決于你提示詞的品質。事實上,不僅語言模型,包括幾個月前很火的 DALL·E,Stable Diffusion 等 AI 文本到圖片的生成模型,提示詞對其生成藝術的風格和品質也有非常大的影響。
![]()
(同樣是漢堡,同樣是 Stable Diffusion 2.1 模型,左邊漢堡中的提示詞哪怕加了 「Trending on Artstation」 也令人沒有胃口。那麼問題來了,右邊的提示詞你能猜到是什麼麼?)
但說起提示詞,難免讓人愛恨交加。愛的人把它視為技術與藝術的融合,恨的人把它看做阻礙機器學習和 AI 前進的絆腳石。
ChatGPT 創始人 Sam Altman 認為提示詞工程(Prompt Engineering)是用自然語言編程的黑科技,絕對是一個高回報的技能。 網絡和論壇上搜集、整理甚至高價出售、懸賞提示詞的比比皆是。很多人把提示詞看做 AIGC 這個時代的源代碼,對應的網課已經開始涌現。
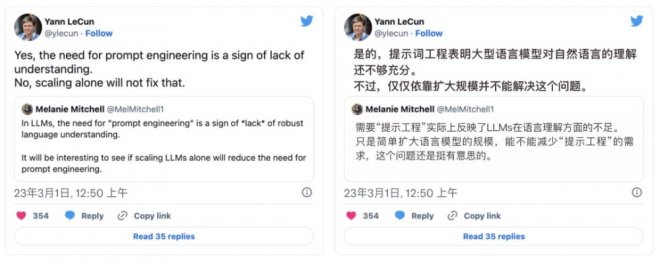
與之相對應的, 人盡所知的深度學習巨頭 Yann LeCun 卻認為,提示詞工程的存在是因為 LLMs 對真實世界理解的不足 。他覺得 LLMs 需要提示詞只是一個臨時態,這恰恰說明了當前 LLMs 還有很大的改進空間。隨著 LLMs 技術的不斷革新,LLMs 很快會具備理解真實世界的能力,到那時提示詞工程就失去了存在的價值。
![]()
未來太遠,但就目前 LLM 的發展來客觀講,提示詞的存在是有一定意義的。正如在現實世界中人與人的互動需要一定的溝通技巧一樣, 你也可以把提示詞看做人與機器互動時的溝通技巧 。好的提示詞可以幫助你在使用 LLMs 時取得更好的結果,這就像在現實世界中,口才出眾、能說會道的人往往可以更快速地協調完成工作。
盡管在 2023 年,自然語言已經魚躍成為了人和人、人和機器之間溝通的統一方式,然而與 LLM 機器 進行溝通還是比與人交談更具挑戰性。首先,LLM 無法像人類一樣理解細微差別、語氣或上下文,這意味著需要仔細設計提示詞,使其明確且易于被模型理解。你可以想象你嘰里咕嚕對 LLM 說了一大堆,然后 LLM 冷淡地回復了一句 「說人話」。其次,由于訓練語料的限制,LLMs 在語言理解方面可能存在一定的局限性,一些現實世界中的長邏輯表達,鋪陳、反轉、甚至是簡單推理歸納在 LLMs 中不能被完美的理解和執行。而 LLMs 中因為訓練語料中而產生的一些暗語(比如 GPT 中最著名的 「Let‘s think step by step / 讓我們一步一步思考」 , 「Below is my best shot / 下面是我最好的一次預測」)在人與人的日常溝通間反而不常見。這些都使得提示詞工程進一步復雜化,晉升為所謂的 「玄學」。
對于母語非英語的中國用戶來說,提示詞也是阻礙大家對 LLMs 嘗鮮的最大痛點。 回想 2022 年暑期 Midjourney、Stable Diffusion 在英語市場如日中天時,國內的社區反應并不熱烈。究其原因,還是因為 Midjourney、Stable Diffusion 的提示詞以英文為主,在構建時需要大量的詞匯和流行文化儲備。這對于想嘗鮮的中文用戶都極其不友好。ChatGPT 之所以能夠在中文社區火爆,一部分原因也得力于其在中文上的良好支持,這極大地降低了中文用戶的門檻。漢語作為世界上使用量數一數二的語言,仍然被提示詞絆了一個小跟頭;自鄶而下,小語種究竟有多難可想而知。
總而言之,提示詞工程的存在具有它的合理性。一個好的提示詞也確實能帶來事半功倍的意義。好的提示詞能夠幫助我們了解大語言模型的能力和邊界,深入挖掘它的潛力,從而在生產實踐中更好地發揮其作用。這其中最著名的例子就是 上下文學習 (In-context learning)。
![]()
用魔法打敗魔法在現實中,提示詞的優化過程需要反復試錯迭代,極其繁瑣;并且還需要一定的知識儲備。這就不禁讓人發問,在 AI 當道的今天,提示詞能不能也自動生成?
在 Yann LeCun 抨擊提示詞的推文回復里,我們注意到了這條回復:「提示詞工程就如同對科學中對待一個問題的描述和定義;同一個問題,在不同人的描述下,或優或劣、或易或難、或可解或不可解。所以,提示詞工程的存在并沒有錯,而且提示詞工程本身也可以被自動化。」 這位網友同時還給出了一個產品: 「最美提示詞」(PromptPerfect.jina.ai)。 也就是說,這種 用算法來優化提示詞 的新范式已經被成功實現了!
![]()
產品體驗鏈接:https://promptperfect.jina.ai
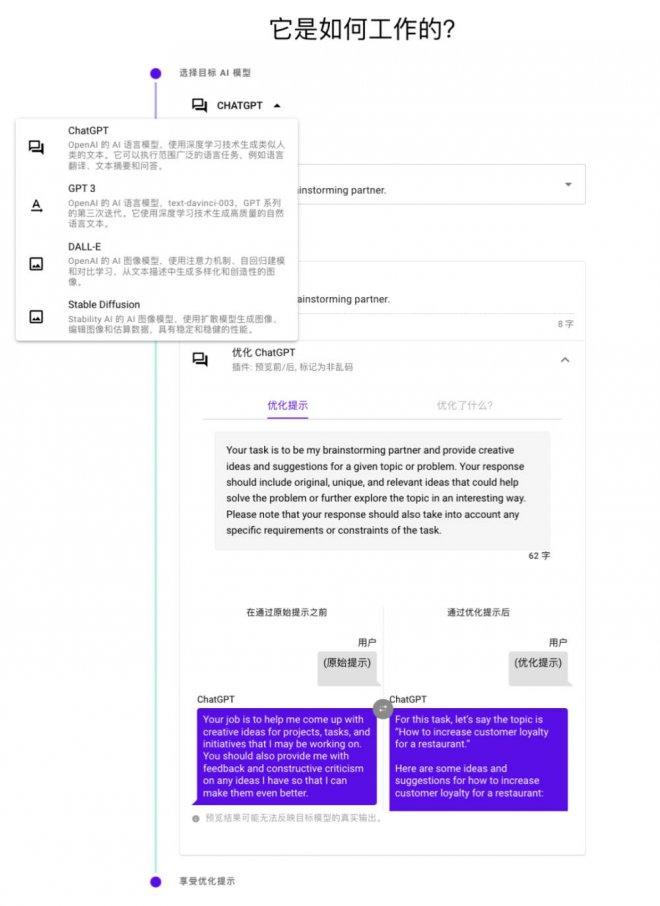
這條回復中提到的 promptperfect.jina.ai 用魔法馴化魔法,讓 AI 指導 AI,當你輸入提示詞后,它就會輸出優化后的「最美提示詞」,并讓你預覽優化前后的模型輸出。這樣就實現了從 「garbage-(prompt)-in-garbage-(content)-out」 到 「好輸入 - 好輸出」 的良性循環。根據產品的官方文檔介紹,其不僅支持當下最火的 ChatGPT 提示詞優化,還支持 GPT 3、Stable Diffusion、Dall-E。接下來就讓我們來測評一下這位 「AI 提示詞工程師」 — 最美提示詞(PromptPerfect)究竟有哪些科技與狠活。
如何 10 秒鐘內輕松優化提示詞?1、將口語需求變成條理清晰的提示詞
優化提示詞需要理解語言的構造,知道哪些句子哪些詞能夠 「啟動」 LLMs 的智能。如果沒有這些儲備,提示詞含糊不清,如口語一團亂麻,那麼就容易被 LLM 帶溝里。「最美提示詞」 可以從海量數據中學習并深入理解更深刻的語言知識,以產生更加準確、清晰、有效的提示詞,不管想要什麼樣的需求和任務,都能 直接量身定制,提供最精準的表述。
![]()
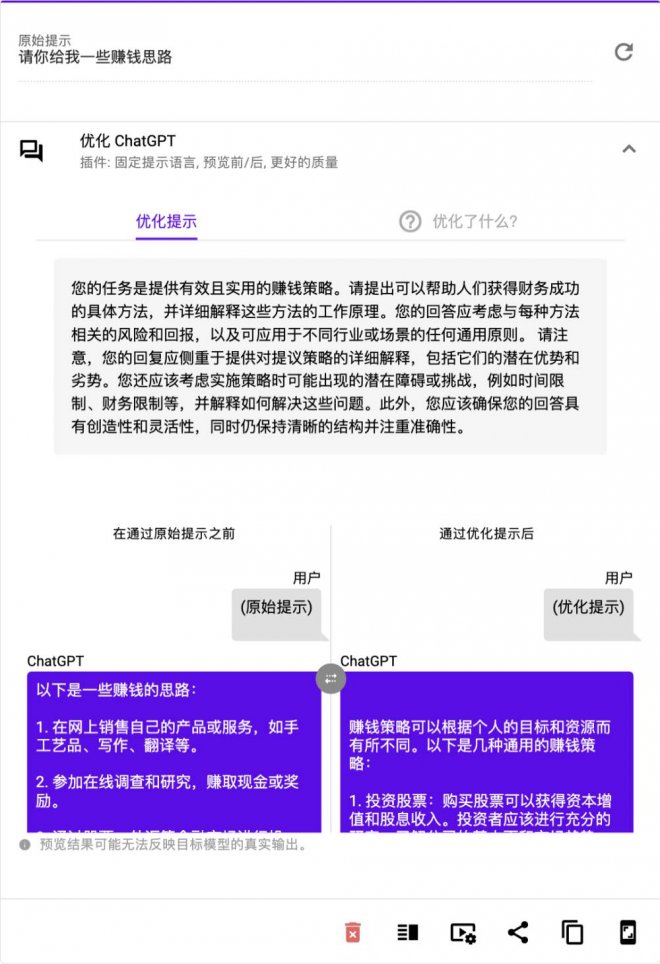
面對 GPT3 或 ChatGPT 時,提示詞卡殼可能是因為溝通能力有限,難以表述清晰的問題或指令,嚴重影響到模型的回答品質。我們嘗試用「最美提示詞」優化一些常見指令,如下圖,「最美提示詞」 把原本簡略粗糙的提示詞 「請給我發一些賺錢思路」 進行了上下文的擴展,輸出了一條堪稱完美的提示詞:
![]()
![]()
手動輸入靠運氣
![]()
使用「最美提示詞」靠科技
相比原始提示詞,「最美提示詞」 定義了明確的目標、清晰的產出,還給 ChatGPT 補充了情景式鋪墊的邏輯 ,使得 ChatGPT 生成的措施更具實操性,效果的確肉眼可見地得到了大幅改善。
2、輕松拿捏不同的 LLMs/LMs 的 「話術」
不同的 LLMs 有不同的脾氣和習慣,想要與他們進行有效溝通,就需要學會當地的話術。否則就很容易形成雞同鴨講。就好比當你好不容易掌握了 Stable Diffusion 咒語,結果發現 ChatGPT 的對話方式就完全不同,一切積累從頭再來。「最美提示詞」 幫用戶就免去了對不同模型的學習成本,不論是 ChatGPT、GPT 3、Stable Diffusion 還是 Dall·E 等, 只要選擇模型,就可以一鍵就能優化最合適的提示詞。
![]()
3、中文提示詞一鍵優化生成完美英文提示詞
跟單模態的 ChatGPT 比起來,在 AI 繪畫領域,英文說不好就是難下筆。就算囤了一堆提示詞,也可能因為詞匯量不夠,不知道怎麼描述,找不到合適的提示詞而郁悶。「最美提示詞」 可以把你用中文想的提示詞直接變成英文的提示詞 ,讓你用起來更順手,效果也更棒,不用再費勁去學習各種英文形容詞,中文用戶也能輕松上手。有時候我們用 DALL・E 或 Stable Diffusion 生成圖片時,會覺得很難出效果。這可能是因為我們英文不夠好,也可能想象力不夠豐富,沒法想出具體的圖像或場景。所以出來的圖片就很模糊或者很奇怪。
我們嘗試用「最美提示詞」優化一些常見指令,比如說,下圖,「最美提示詞」把原來簡單粗糙,略顯無聊的 「印象派的北京街景」 改成了一句帶有豐富描述,超級贊的英文!
![]()
![]()
![]()
優化前的提示詞完全顯示不出來印象派、耳機、未來風格
AI 繪畫的提示詞測試起來更加一目了然,「最美提示詞」生成了冗長但無比精準的 「咒語」,直接提升了原始提示詞的審美、想象和閱歷,使得畫面更生動,更準確地表達了我們原本的期望。
4、開發者可直接調用的 API
想要大批量優化提示詞,或是直接在現有系統中集成,那麼 可以直接調用「最美提示詞」的 API ,這樣可以更快地生成批量的優質提示詞 ,不管你需要多少個提示詞,「最美提示詞」都能為你快速完成,提供最優質的服務。
![]()
背后的技術與團隊我們注意到「最美提示詞」自 2 月 28 日一經推出以來,就引發了大量關注,大家都想要用它來優化各種場景的提示詞。短短 幾天之內 就吸引了 數千用戶 優化了近萬提示詞,在各類平台狂攬好評。畢竟只要用了它生成的提示詞,就能讓大模型出來的東西既有創意又有美感。
「最美提示詞」要給各種語言模型找到最好的提示詞,它用了兩招高級的機器學習技術: 強化學習和上下文學習 。強化學習就是它的教練,一直在給它灌輸知識和經驗,讓它變得越來越厲害。它先用一些人工篩選的提示詞給一個預訓練模型打好基礎,再根據用戶輸入和模型輸出來調整提示詞網絡策略。比如說,當我們要優化 DALL・E 和 Stable Diffusion 的提示詞時,我們要讓生成的內容既有關聯又有美感,就像教練要求運動員在各方面都表現得非常優秀。
上下文學習就是它的老師,通過多個例子來教它怎麼學。但是它不是把所有的例子都堆在一起,而是把很多的例子分成幾組,然后讓語言模型自己去編碼。這樣「最美提示詞」就可以用更多的例子來教模型,從而生成更準確、更有效的提示詞。通過用這兩招,「最美提示詞」就可以為各種語言模型優化提示詞,顯著提升效率和準確度,就像一個由教練和老師一起培養出來的頂尖運動員。
這種大規模的生成式模型,無論是語言生成模型還是多模態的生成式模型,在目前是以語言為主。 然而,在未來,我們肯定會看到更多多模態的生成式模型的出現。 我們發現「最美提示詞」的研發團隊其實正是專注于多模態 AI 的新興技術公司 Jina AI ,成立于 2020 年,總部位于德國柏林,在北京深圳均設有研發。Jina AI 專注于多模態 AI 技術研發,在搜索和生成領域都有廣泛的應用,此前 Jina AI 已經發布了一系列如下的開源的項目,在 GitHub 累計收到來自全球開發者將近四萬星星的關注,為開發者快速實現多模態 AI 應用提供了方便:
多模態 MLOps 框架 Jina:
https://github.com/jina-ai/jina
專為多模態數據而生的數據結構DocArray:
github.com/docarray/docarray
CLIP-as-service:
github.com/jina-ai/clip-as-service
![]()
![]()
![]()
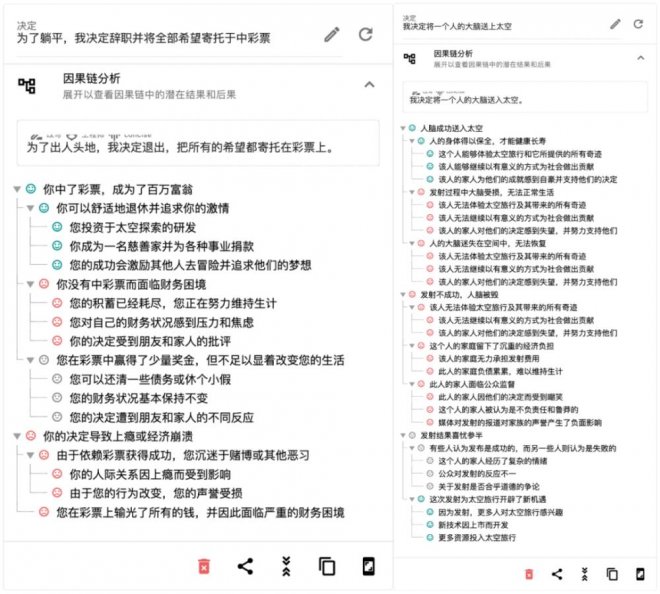
產品體驗鏈接:https://rationale.jina.ai
隨著 ChatGPT API 的開放,2023 年面向 C 端的 AI 應用就像 2000 年互聯網時代一樣,形成井噴式大爆發:每天都有數以百計的 ChatGPT API 的應用面世,它們遍布各個領域,打破了現有的規則,并顛覆了多個領域的生態。一些傳統巨頭面臨挑戰,一些傳統的壁壘面臨打破,一些傳統行業面臨革新。而對于我們來說,想要在 AI 新時代站穩腳跟,就得站在巨人的肩膀上,吟誦出完美的咒語,用魔法來解決各類生成任務, 畢竟完美的提示詞就是一個 ChatGPT 應用的靈魂所在。
[圖擷取自網路,如有疑問請私訊]

如果將 ChatGPT 比喻成哈利波特小說中的絢麗魔法,那麼提示詞就像召喚魔法時的咒語。 能不能用好這個魔法,取決于你念咒語時是清晰明確,還是夾雜著 「口音」。 同樣一個魔法,念咒的人不同,威力也不盡相同。所謂一千個讀者就有一千個哈姆雷特,但一千個巫師的阿瓦達索命咒也不及伏地魔一個人念的有效(當然伏地魔念得再好也不如哈利念得有效)。
所以,能不能用好 ChatGPT 和大規模語言模型,很大程度上取決于你提示詞的品質。事實上,不僅語言模型,包括幾個月前很火的 DALL·E,Stable Diffusion 等 AI 文本到圖片的生成模型,提示詞對其生成藝術的風格和品質也有非常大的影響。

(同樣是漢堡,同樣是 Stable Diffusion 2.1 模型,左邊漢堡中的提示詞哪怕加了 「Trending on Artstation」 也令人沒有胃口。那麼問題來了,右邊的提示詞你能猜到是什麼麼?)
但說起提示詞,難免讓人愛恨交加。愛的人把它視為技術與藝術的融合,恨的人把它看做阻礙機器學習和 AI 前進的絆腳石。
ChatGPT 創始人 Sam Altman 認為提示詞工程(Prompt Engineering)是用自然語言編程的黑科技,絕對是一個高回報的技能。 網絡和論壇上搜集、整理甚至高價出售、懸賞提示詞的比比皆是。很多人把提示詞看做 AIGC 這個時代的源代碼,對應的網課已經開始涌現。
與之相對應的, 人盡所知的深度學習巨頭 Yann LeCun 卻認為,提示詞工程的存在是因為 LLMs 對真實世界理解的不足 。他覺得 LLMs 需要提示詞只是一個臨時態,這恰恰說明了當前 LLMs 還有很大的改進空間。隨著 LLMs 技術的不斷革新,LLMs 很快會具備理解真實世界的能力,到那時提示詞工程就失去了存在的價值。
未來太遠,但就目前 LLM 的發展來客觀講,提示詞的存在是有一定意義的。正如在現實世界中人與人的互動需要一定的溝通技巧一樣, 你也可以把提示詞看做人與機器互動時的溝通技巧 。好的提示詞可以幫助你在使用 LLMs 時取得更好的結果,這就像在現實世界中,口才出眾、能說會道的人往往可以更快速地協調完成工作。
盡管在 2023 年,自然語言已經魚躍成為了人和人、人和機器之間溝通的統一方式,然而與 LLM 機器 進行溝通還是比與人交談更具挑戰性。首先,LLM 無法像人類一樣理解細微差別、語氣或上下文,這意味著需要仔細設計提示詞,使其明確且易于被模型理解。你可以想象你嘰里咕嚕對 LLM 說了一大堆,然后 LLM 冷淡地回復了一句 「說人話」。其次,由于訓練語料的限制,LLMs 在語言理解方面可能存在一定的局限性,一些現實世界中的長邏輯表達,鋪陳、反轉、甚至是簡單推理歸納在 LLMs 中不能被完美的理解和執行。而 LLMs 中因為訓練語料中而產生的一些暗語(比如 GPT 中最著名的 「Let‘s think step by step / 讓我們一步一步思考」 , 「Below is my best shot / 下面是我最好的一次預測」)在人與人的日常溝通間反而不常見。這些都使得提示詞工程進一步復雜化,晉升為所謂的 「玄學」。
對于母語非英語的中國用戶來說,提示詞也是阻礙大家對 LLMs 嘗鮮的最大痛點。 回想 2022 年暑期 Midjourney、Stable Diffusion 在英語市場如日中天時,國內的社區反應并不熱烈。究其原因,還是因為 Midjourney、Stable Diffusion 的提示詞以英文為主,在構建時需要大量的詞匯和流行文化儲備。這對于想嘗鮮的中文用戶都極其不友好。ChatGPT 之所以能夠在中文社區火爆,一部分原因也得力于其在中文上的良好支持,這極大地降低了中文用戶的門檻。漢語作為世界上使用量數一數二的語言,仍然被提示詞絆了一個小跟頭;自鄶而下,小語種究竟有多難可想而知。
總而言之,提示詞工程的存在具有它的合理性。一個好的提示詞也確實能帶來事半功倍的意義。好的提示詞能夠幫助我們了解大語言模型的能力和邊界,深入挖掘它的潛力,從而在生產實踐中更好地發揮其作用。這其中最著名的例子就是 上下文學習 (In-context learning)。

用魔法打敗魔法在現實中,提示詞的優化過程需要反復試錯迭代,極其繁瑣;并且還需要一定的知識儲備。這就不禁讓人發問,在 AI 當道的今天,提示詞能不能也自動生成?
在 Yann LeCun 抨擊提示詞的推文回復里,我們注意到了這條回復:「提示詞工程就如同對科學中對待一個問題的描述和定義;同一個問題,在不同人的描述下,或優或劣、或易或難、或可解或不可解。所以,提示詞工程的存在并沒有錯,而且提示詞工程本身也可以被自動化。」 這位網友同時還給出了一個產品: 「最美提示詞」(PromptPerfect.jina.ai)。 也就是說,這種 用算法來優化提示詞 的新范式已經被成功實現了!
產品體驗鏈接:https://promptperfect.jina.ai
這條回復中提到的 promptperfect.jina.ai 用魔法馴化魔法,讓 AI 指導 AI,當你輸入提示詞后,它就會輸出優化后的「最美提示詞」,并讓你預覽優化前后的模型輸出。這樣就實現了從 「garbage-(prompt)-in-garbage-(content)-out」 到 「好輸入 - 好輸出」 的良性循環。根據產品的官方文檔介紹,其不僅支持當下最火的 ChatGPT 提示詞優化,還支持 GPT 3、Stable Diffusion、Dall-E。接下來就讓我們來測評一下這位 「AI 提示詞工程師」 — 最美提示詞(PromptPerfect)究竟有哪些科技與狠活。
如何 10 秒鐘內輕松優化提示詞?1、將口語需求變成條理清晰的提示詞
優化提示詞需要理解語言的構造,知道哪些句子哪些詞能夠 「啟動」 LLMs 的智能。如果沒有這些儲備,提示詞含糊不清,如口語一團亂麻,那麼就容易被 LLM 帶溝里。「最美提示詞」 可以從海量數據中學習并深入理解更深刻的語言知識,以產生更加準確、清晰、有效的提示詞,不管想要什麼樣的需求和任務,都能 直接量身定制,提供最精準的表述。

面對 GPT3 或 ChatGPT 時,提示詞卡殼可能是因為溝通能力有限,難以表述清晰的問題或指令,嚴重影響到模型的回答品質。我們嘗試用「最美提示詞」優化一些常見指令,如下圖,「最美提示詞」 把原本簡略粗糙的提示詞 「請給我發一些賺錢思路」 進行了上下文的擴展,輸出了一條堪稱完美的提示詞:
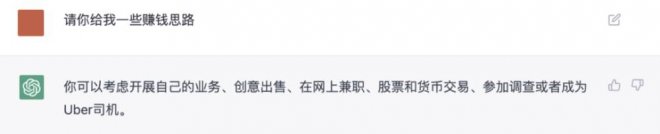
手動輸入靠運氣

使用「最美提示詞」靠科技
相比原始提示詞,「最美提示詞」 定義了明確的目標、清晰的產出,還給 ChatGPT 補充了情景式鋪墊的邏輯 ,使得 ChatGPT 生成的措施更具實操性,效果的確肉眼可見地得到了大幅改善。
2、輕松拿捏不同的 LLMs/LMs 的 「話術」
不同的 LLMs 有不同的脾氣和習慣,想要與他們進行有效溝通,就需要學會當地的話術。否則就很容易形成雞同鴨講。就好比當你好不容易掌握了 Stable Diffusion 咒語,結果發現 ChatGPT 的對話方式就完全不同,一切積累從頭再來。「最美提示詞」 幫用戶就免去了對不同模型的學習成本,不論是 ChatGPT、GPT 3、Stable Diffusion 還是 Dall·E 等, 只要選擇模型,就可以一鍵就能優化最合適的提示詞。
3、中文提示詞一鍵優化生成完美英文提示詞
跟單模態的 ChatGPT 比起來,在 AI 繪畫領域,英文說不好就是難下筆。就算囤了一堆提示詞,也可能因為詞匯量不夠,不知道怎麼描述,找不到合適的提示詞而郁悶。「最美提示詞」 可以把你用中文想的提示詞直接變成英文的提示詞 ,讓你用起來更順手,效果也更棒,不用再費勁去學習各種英文形容詞,中文用戶也能輕松上手。有時候我們用 DALL・E 或 Stable Diffusion 生成圖片時,會覺得很難出效果。這可能是因為我們英文不夠好,也可能想象力不夠豐富,沒法想出具體的圖像或場景。所以出來的圖片就很模糊或者很奇怪。
我們嘗試用「最美提示詞」優化一些常見指令,比如說,下圖,「最美提示詞」把原來簡單粗糙,略顯無聊的 「印象派的北京街景」 改成了一句帶有豐富描述,超級贊的英文!
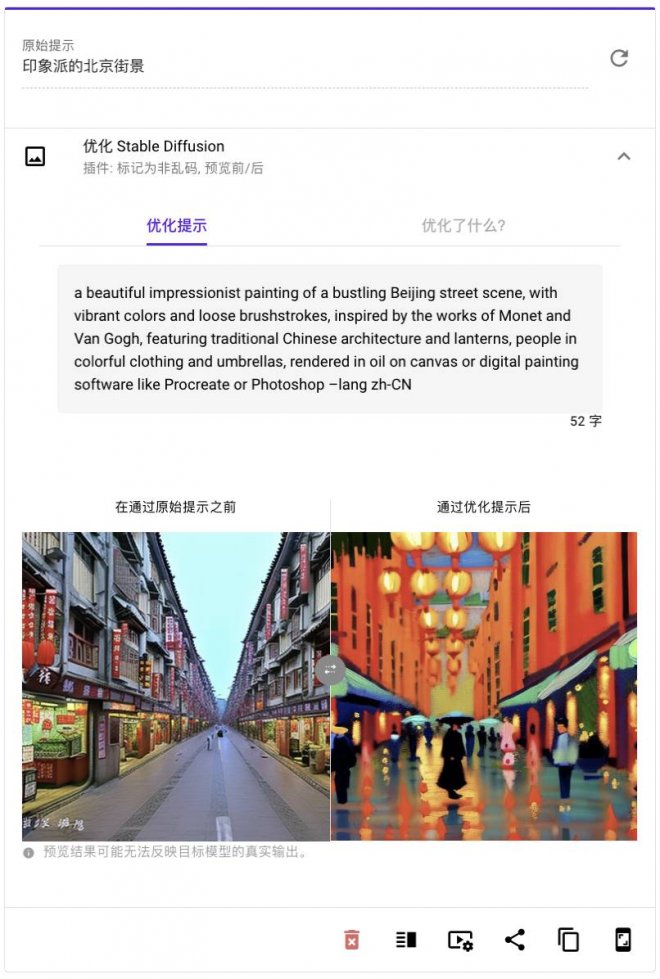


優化前的提示詞完全顯示不出來印象派、耳機、未來風格
AI 繪畫的提示詞測試起來更加一目了然,「最美提示詞」生成了冗長但無比精準的 「咒語」,直接提升了原始提示詞的審美、想象和閱歷,使得畫面更生動,更準確地表達了我們原本的期望。
4、開發者可直接調用的 API
想要大批量優化提示詞,或是直接在現有系統中集成,那麼 可以直接調用「最美提示詞」的 API ,這樣可以更快地生成批量的優質提示詞 ,不管你需要多少個提示詞,「最美提示詞」都能為你快速完成,提供最優質的服務。

背后的技術與團隊我們注意到「最美提示詞」自 2 月 28 日一經推出以來,就引發了大量關注,大家都想要用它來優化各種場景的提示詞。短短 幾天之內 就吸引了 數千用戶 優化了近萬提示詞,在各類平台狂攬好評。畢竟只要用了它生成的提示詞,就能讓大模型出來的東西既有創意又有美感。
「最美提示詞」要給各種語言模型找到最好的提示詞,它用了兩招高級的機器學習技術: 強化學習和上下文學習 。強化學習就是它的教練,一直在給它灌輸知識和經驗,讓它變得越來越厲害。它先用一些人工篩選的提示詞給一個預訓練模型打好基礎,再根據用戶輸入和模型輸出來調整提示詞網絡策略。比如說,當我們要優化 DALL・E 和 Stable Diffusion 的提示詞時,我們要讓生成的內容既有關聯又有美感,就像教練要求運動員在各方面都表現得非常優秀。
上下文學習就是它的老師,通過多個例子來教它怎麼學。但是它不是把所有的例子都堆在一起,而是把很多的例子分成幾組,然后讓語言模型自己去編碼。這樣「最美提示詞」就可以用更多的例子來教模型,從而生成更準確、更有效的提示詞。通過用這兩招,「最美提示詞」就可以為各種語言模型優化提示詞,顯著提升效率和準確度,就像一個由教練和老師一起培養出來的頂尖運動員。
這種大規模的生成式模型,無論是語言生成模型還是多模態的生成式模型,在目前是以語言為主。 然而,在未來,我們肯定會看到更多多模態的生成式模型的出現。 我們發現「最美提示詞」的研發團隊其實正是專注于多模態 AI 的新興技術公司 Jina AI ,成立于 2020 年,總部位于德國柏林,在北京深圳均設有研發。Jina AI 專注于多模態 AI 技術研發,在搜索和生成領域都有廣泛的應用,此前 Jina AI 已經發布了一系列如下的開源的項目,在 GitHub 累計收到來自全球開發者將近四萬星星的關注,為開發者快速實現多模態 AI 應用提供了方便:
多模態 MLOps 框架 Jina:
https://github.com/jina-ai/jina
專為多模態數據而生的數據結構DocArray:
github.com/docarray/docarray
CLIP-as-service:
github.com/jina-ai/clip-as-service

產品體驗鏈接:https://rationale.jina.ai
隨著 ChatGPT API 的開放,2023 年面向 C 端的 AI 應用就像 2000 年互聯網時代一樣,形成井噴式大爆發:每天都有數以百計的 ChatGPT API 的應用面世,它們遍布各個領域,打破了現有的規則,并顛覆了多個領域的生態。一些傳統巨頭面臨挑戰,一些傳統的壁壘面臨打破,一些傳統行業面臨革新。而對于我們來說,想要在 AI 新時代站穩腳跟,就得站在巨人的肩膀上,吟誦出完美的咒語,用魔法來解決各類生成任務, 畢竟完美的提示詞就是一個 ChatGPT 應用的靈魂所在。
[圖擷取自網路,如有疑問請私訊]
|
本篇 |
不想錯過? 請追蹤FB專頁! |
| 喜歡這篇嗎?快分享吧! |








相關文章





科普解密